2 Probability
The usual touchstone of whether what someone asserts is mere persuasion or at least a subjective conviction, i.e., firm belief, is betting. Often someone pronounces his propositions with such confident and inflexible defiance that he seems to have entirely laid aside all concern for error. A bet disconcerts him. Sometimes he reveals that he is persuaded enough for one ducat but not for ten. For he would happily bet one, but at ten he suddenly becomes aware of what he had not previously noticed, namely that it is quite possible that he has erred. -— Immanuel Kant, Critique of Pure Reason
The central tension, and opportunity, in data science is the interplay between the data and the science, between our empirical observations and the models which we create to use them. Probability is the language we use to explore that interplay; it connects data to models, and models to inference.
What does it mean that Donald Trump had a 30% chance of winning election in the fall of 2016? That there is a 90% probability of rain tomorrow? That the dice at the casino are fair?
Probability quantifies uncertainty. Think of probability as a proportion. The probability of an event occurring is a number from 0 to 1, where 0 means that the event is impossible and 1 means that the event is 100% certain.
Begin with the simplest events: coin flips and dice rolls. The set of all outcomes is the sample space. With fair coins and dice, we know that:
- The probability of rolling a 1 or a 2 is 2/6, or 1/3.
- The probability of rolling a 1, 2, 3, 4, 5, or 6 is 1.
- The probability of flipping a coin and getting tails is 1/2.
If the probability of an outcome is unknown, we will often refer to it as an unknown parameter, something which we might use data to estimate. We usually use Greek letters to refer to parameters. Whenever we are talking about a specific probability (represented by a single value), we will use \(\rho\) (the Greek letter “rho” but spoken aloud as “p” by us) with a subscript which specifies the exact outcome of which it is the probability. For instance, \(\rho_h = 0.5\) denotes the probability of getting heads on a coin toss when the coin is fair. \(\rho_t\) — spoken as “PT” or “P sub T” or “P tails” — denotes the probability of getting tails on a coin toss. This notation can become annoying if the outcome whose probability we seek is less concise. For example, we might write the probability of rolling a 1, 2 or 3 using a fair six-sided dice as:
\[ \rho_{dice\ roll\ is\ 1,\ 2\ or\ 3} = 0.5 \]
We will rarely write out the full definition of an event along with the \(\rho\) symbol. The syntax is just too ugly. Instead, we will define an event a as the case when one rolled dice equals 1, 2 or 3 and, then, write
\[\rho_a = 0.5\]
A random variable is a function which produces a value from a sample set. A random variable can be either discrete — where the sample set has a limited number of members, like H or T for the result of a coin flip, or 2, 3, …, 12 for the sum of two dice — or continuous (any value within a range). Probability is a claim about the value of a random variable, i.e., that you have a 50% probability of getting a 1, 2 or 3 when you roll a fair dice.
We usually use capital letters for random variables. So, \(C\) might be our symbol for the random variable which is a coin toss and \(D\) might be our symbol for the random variable which is the sum of two dice. When discussing random variables in general, or when we grow tired of coming up with new symbols, we will use \(Y\).
Small letters refer to a single outcome or result from a random variable. \(c\) is the outcome from one coin toss. \(d\) is the result from one throw of the two dice. The value of the outcome must come from the sample space. So, \(c\) can only take on two possible values: heads or tails. When discussing random variables in general, we use \(y\) to refer to one outcome of the random variable \(Y\). If there are multiple outcomes — if we have, for example, flipped the coin multiple times — then we use subscripts to indicate the separate outcomes: \(y_1\), \(y_2\), and so on. The symbol for an arbitrary outcome is \(y_i\), where \(i\) ranges from 1 through \(N\), the total number of events or experiments for which an outcome \(y\) was produced.
The only package we need in this chapter is tidyverse.
To understand probability more fully, we first need to understand distributions.
2.1 Distributions
A variable in a tibble is a column, a vector of values. We sometimes refer to this vector as a “distribution.” This is somewhat sloppy in that a distribution can be many things, most commonly a mathematical formula. But, strictly speaking, a “frequency distribution” or an “empirical distribution” is a list of values, so this usage is not unreasonable.
2.1.1 Scaling distributions
Consider the vector which is the result of rolling one dice 10 times.
ten_rolls <- c(5, 5, 1, 5, 4, 2, 6, 2, 1, 5)There are other ways of storing the data in this vector. Instead of reporting every observation, we could record the number of times each value appears or the percentage of the total which this number accounts for.
Show the code
tibble(outcome = ten_rolls) |>
summarise(n = n(), .by = outcome) |>
mutate(portion = n / sum(n)) |>
arrange(outcome) |>
gt() |>
tab_header(title = "Distribution of Ten Rolls of a Fair Dice",
subtitle = "Counts and percentages reflect the same information") |>
cols_label(outcome = "Outcome",
n = "Count",
portion = "Percentage") |>
fmt_percent(columns = c(portion), decimals = 0)| Distribution of Ten Rolls of a Fair Dice | ||
|---|---|---|
| Counts and percentages reflect the same information | ||
| Outcome | Count | Percentage |
| 1 | 2 | 20% |
| 2 | 2 | 20% |
| 4 | 1 | 10% |
| 5 | 4 | 40% |
| 6 | 1 | 10% |
In this case, with only 10 values, it is actually less efficient to store the data like this. But what happens when we have 1,000 rolls?
Show the code
set.seed(89)
tibble(outcome = sample(1:6, size = 1000, replace = TRUE)) |>
summarise(n = n(), .by = outcome) |>
mutate(portion = n / sum(n)) |>
arrange(outcome) |>
gt() |>
tab_header(title = "Distribution of One Thousand Rolls of a Fair Dice",
subtitle = "Counts and percentages reflect the same information") |>
cols_label(outcome = "Outcome",
n = "Count",
portion = "Percentage") |>
fmt_percent(columns = c(portion), decimals = 0)| Distribution of One Thousand Rolls of a Fair Dice | ||
|---|---|---|
| Counts and percentages reflect the same information | ||
| Outcome | Count | Percentage |
| 1 | 190 | 19% |
| 2 | 138 | 14% |
| 3 | 160 | 16% |
| 4 | 173 | 17% |
| 5 | 169 | 17% |
| 6 | 170 | 17% |
Instead of keeping around a vector of length 1,000, we can just keep 12 values — the 6 possible outcomes and their frequency — without losing any information.
Two distributions can be identical even if they are of very different lengths. Let’s compare our original distribution of 10 rolls of the dice with another distribution which just features 100 copies of those 10 rolls.
more_rolls <- rep(ten_rolls, 100)Show the code

The two graphs have the exact same shape because, even though the vectors are of different lengths, the relative proportions of the outcomes are identical. In some sense, both vectors are from the same distribution. Relative proportions, not the total counts, are what matter.
2.1.2 Normalizing distributions
If two distributions have the same shape, then they only differ by the labels on the y-axis. There are various ways of “normalizing” distributions so as to place them all on the same scale. The most common scale is one in which the area under the distribution adds to 1, e.g., 100%. For example, we can transform the above plots:
Show the code
rolls_p <- tibble(value = ten_rolls) |>
ggplot(aes(x = value)) +
geom_bar(aes(y = after_stat(count/sum(count)))) +
labs(title = "Distribution of 10 Rolls",
y = "Percentage") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
more_rolls_p <- tibble(value = more_rolls) |>
ggplot(aes(value)) +
geom_bar(aes(y = after_stat(count/sum(count)))) +
labs(title = "Distribution of 1,000 Rolls",
y = NULL) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))
rolls_p + more_rolls_p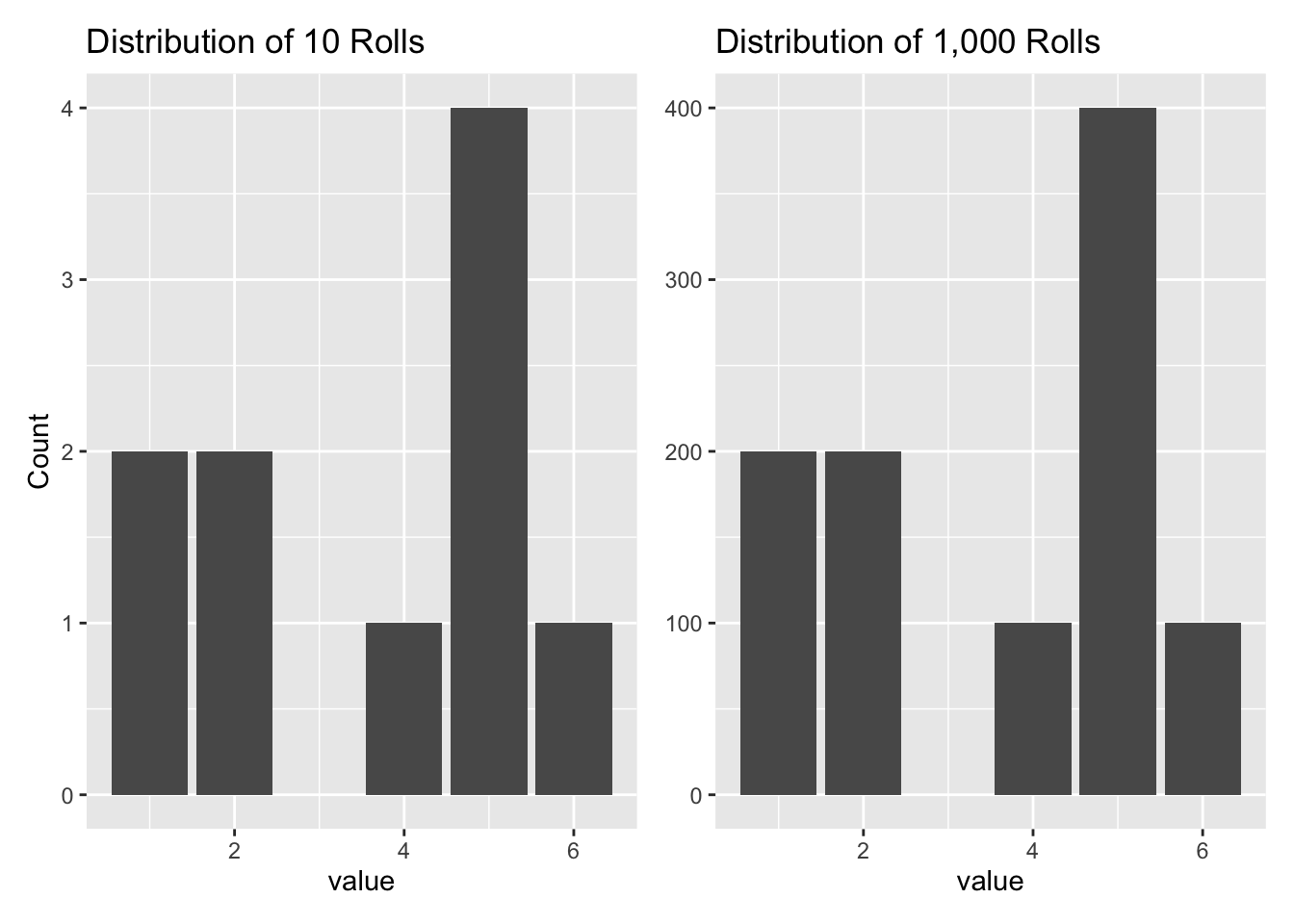
We sometimes refer to a distribution as “unnormalized” if the area under the curve does not add up to 1.
2.1.3 Simulating distributions
There are two distinct concepts: a distribution and a set values drawn from that distribution. But, in typical usage, we employ “distribution” for both. When given a distribution (meaning a vector of numbers), we often use geom_histogram() or geom_density() to display it. But, sometimes, we don’t want to look at the whole thing. We just want some summary measures which report the key aspects of the distribution. The two most important attributes of a distribution are its center and its variation around that center.
We use summarize() to calculate statistics for a variable, a column, a vector of values, or a distribution. Note the language sloppiness. For the purposes of this book, “variable,” “column,” “vector,” and “distribution” all mean the same thing. Other popular statistical functions include: mean(), median(), min(), max(), n() and sum(). Functions which may be new to you include three measures of the “spread” of a distribution: sd() (the standard deviation), mad() (the scaled median absolute deviation) and quantile(), which is used to calculate an interval which includes a specified proportion of the values.
Think of the distribution of a variable as an urn from which we can pull out, at random, values for that variable. Drawing a thousand or so values from that urn, and then looking at a histogram, can show where the values are centered and how they vary. Because people are sloppy, they will use the word distribution to refer to at least three related entities:
- the (imaginary!) urn from which we are drawing values.
- all the values in the urn
- all the values which we have drawn from the urn, whether that be 10 or 1,000
Sloppiness in the usage of the word distribution is universal. However, keep three distinct ideas separate:
The unknown true distribution which, in reality, generates the data which we see. Outside of stylized examples in which we assume that a distribution follows a simple mathematical formula, we will never have access to the unknown true distribution. We can only estimate it. This unknown true distribution is often referred to as the data generating mechanism, or DGM. It is a function or black box or urn which produces data. We can see the data. We can’t see the urn.
The estimated distribution which, we think, generates the data which we see. Again, we can never know the unknown true distribution. But, by making some assumptions and using the data we have, we can estimate a distribution. Our estimate may be very close to the true distribution. Or it may be far away. The main task of data science to to create and use these estimated distributions. Almost always, these distributions are instantiated in computer code. Just as there is a true data generating mechanism associated with the (unknown) true distribution, there is an estimated data generating mechanism associated with the estimated ditribution.
A vector of numbers drawn from the estimated distribution. Both true and estimated distributions can be complex animals, difficult to describe accurately and in detail. But a vector of numbers drawn from a distribution is easy to understand and use. So, in general, we work with vectors of numbers. When someone — either a colleague or a piece of R code — creates a distribution which we want to use to answer a question, we don’t really want the distribution itself. Rather, we want a vector of “draws” from that distribution. Vectors are easy to work with! Complex computer code is not.
Again, people (including us!) will often be sloppy and use the same word, “distribution,” without making it clear whether they are talking about the true distribution, the estimated distribution, or a vector of draws from the estimated distribution. The same sloppiness applies to the use of the term data generating mechanism. Try not to be sloppy.
2.2 Probability distributions
Show the code
knitr::include_graphics("probability/images/de_finetti.jpg")
For the purposes of this Primer, a probability distribution is a mathematical object which maps a set of outcomes to probabilities, where each distinct outcome has a chance of occurring between 0 and 1 inclusive. The probabilities must sum to 1. The set of possible outcomes, i.e., the sample space — heads and tails for the coin, 1 through 6 for a single dice, 2 through 12 for the sum of a pair of dice — can be either discrete or continuous. Discrete data can only take on certain values. Continuous data, like height and weight, can take any value within a range. The set of outcomes is the domain of the probability distribution. The range is the associated probabilities.
Assume that a probability distribution is created by a probability function, a set function which maps outcomes to probabilities. The concept of a “probability function” is often split into two categories: probability mass functions (for discrete random variables) and probability density functions (for continuous random variables). As usual, we will be a bit sloppy, using the term probability distribution for both the mapping itself and for the function which creates the mapping.
We discuss three types of probability distributions: empirical, mathematical, and posterior.
The key difference between a distribution, as we have explored them in Section 2.1, and a probability distribution is the requirement that the sum of the probabilities of the individual outcomes must be exactly 1. There is no such requirement for a distribution in general. But any distribution can be turned into a probability distribution by “normalizing” it. In this context, we will often refer to a distribution which is not (yet) a probability distribution as an “unnormalized” distribution.
Pay attention to notation. Recall that when we are talking about a specific probability (represented by a single value), we will use \(\rho\) (the Greek letter “rho”) with a subscript which specifies the exact outcome of which it is the probability. For instance, \(\rho_h = 0.5\) denotes the probability of getting heads on a coin toss when the coin is fair. \(\rho_t\) — spoken as “PT” or “P sub T” or “P tails” — denotes the probability of getting tails on a coin toss. However, when we are referring to the entire probability distribution over a set of outcomes, we will use \(P()\). For example, the probability distribution of a coin toss is \(P(\text{coin})\). That is, \(P(\text{coin})\) is composed of the two specific probabilities (e.g., 60% and 40% for a biased coin) mapped from the two values in the domain (heads and tails). Similarly, \(P(\text{sum of two dice})\) is the probability distribution over the set of 11 outcomes (2 through 12) which are possible when you take the sum of two dice. \(P(\text{sum of two dice})\) is made up of 11 numbers — \(\rho_2\), \(\rho_3\), …, \(\rho_{12}\) — each representing the unknown probability that the sum will equal their value. That is, \(\rho_2\) is the probability of rolling a 2.
A distribution is a function that shows the possible values of a variable and how often they occur.
2.2.1 Flipping a coin
Data science problems start with a question. Example:
What are the chances of getting three heads in a row when flipping a fair coin?
Questions are answered with the help of probability distributions.
An empirical distribution is based on data. Think of this as the probability distribution created by collecting data in the real world or by running a simulation on your computer. In theory, if we increase the number of coins we flip (either in reality or via simulation), the empirical distribution will look more and more similar to the mathematical distribution. The mathematical distribution is the Platonic form. The empirical distribution will often look like the mathematical probability distribution, but it will rarely be exactly the same.
In this simulation, there are 44 heads and 56 tails. The outcome will vary every time we run the simulation, but the proportion of heads to tails should not be too different if the coin is fair.
Show the code
# We are flipping one fair coin a hundreds times. We need to get the same result
# each time we create this graphic because we want the results to match the
# description in the text. Using set.seed() guarantees that the random results
# are the same each time. We define 0 as tails and 1 as heads.
set.seed(3)
tibble(results = sample(c(0, 1), 100, replace = TRUE)) |>
ggplot(aes(x = results)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 0.5,
color = "white") +
labs(title = "Empirical Probability Distribution",
subtitle = "Flipping one coin a hundred times",
x = "Outcome\nResult of Coin Flip",
y = "Probability") +
scale_x_continuous(breaks = c(0, 1),
labels = c("Heads", "Tails")) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()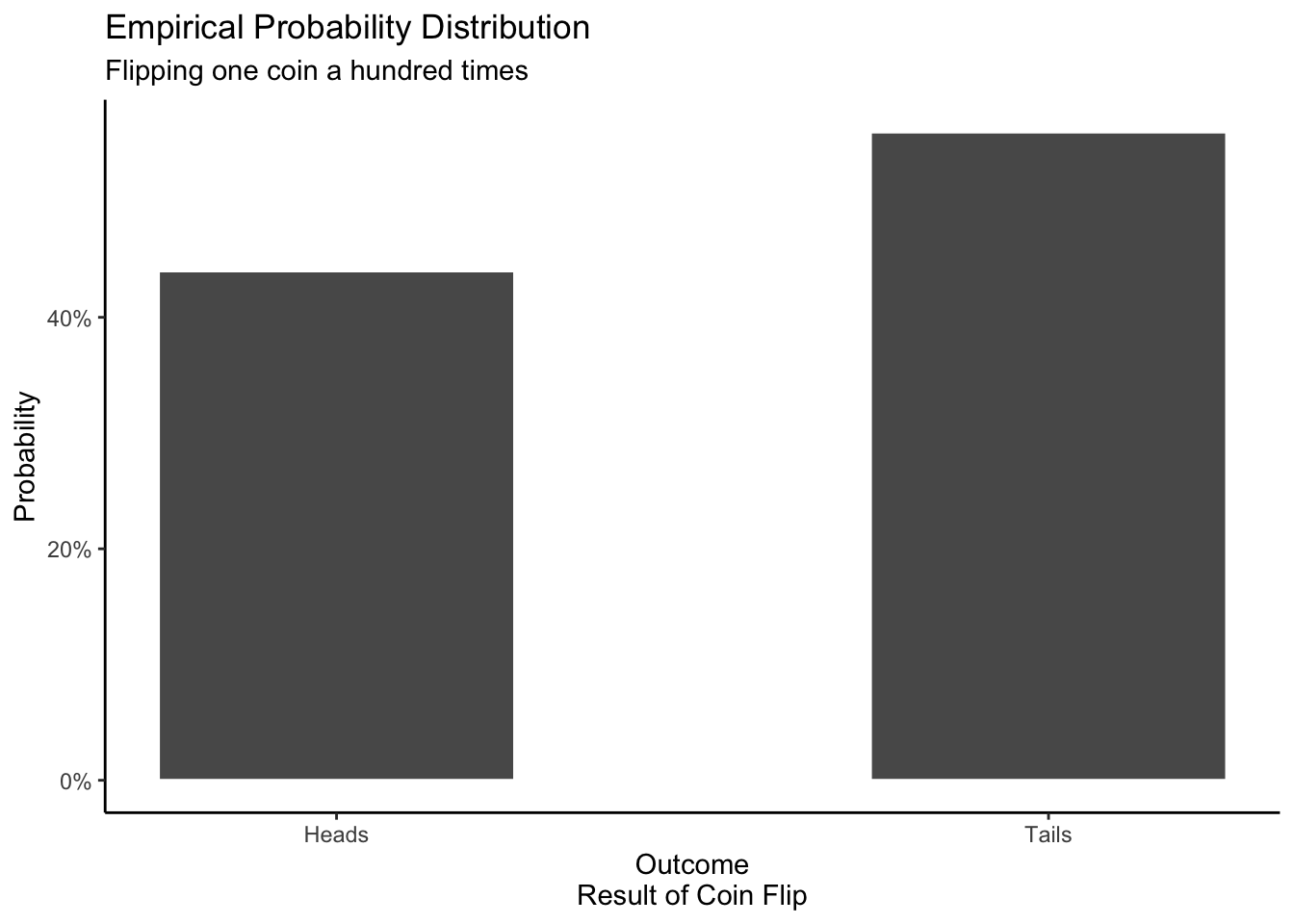
A mathematical distribution is based on a mathematical formula. Assuming that the coin is perfectly fair, we should, on average, get heads as often as we get tails.
Show the code
# The mathematical case with the expected 50/50 outcome hard-coded.
tibble(results = c(rep(0, 50),
rep(1, 50))) |>
ggplot(aes(x = results)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 0.5,
color = "white") +
labs(title = "Mathematical Probability Distribution",
subtitle = "Expectations for flipping a fair coin",
x = "Outcome\nResult of Coin Flip",
y = "Probability") +
scale_x_continuous(breaks = c(0, 1),
labels = c("Heads", "Tails")) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()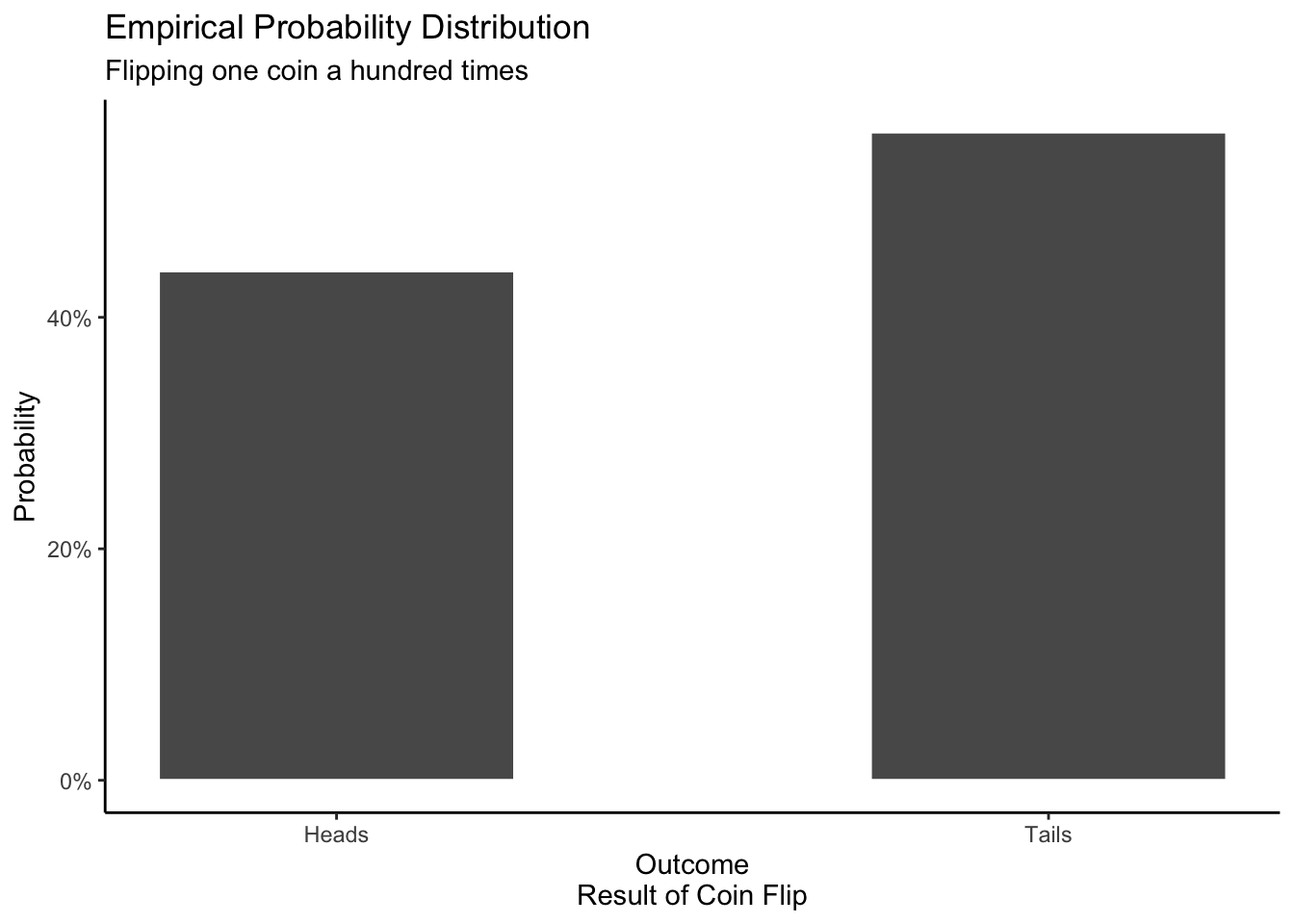
The distribution of a single observation is described by this formula.
\[ P(Y = y) = \begin{cases} 1/2 &\text{for }y= \text{Heads}\\ 1/2 &\text{for }y= \text{Tails} \end{cases}\] We sometimes do not know that the probability of heads and the probability of tails both equal 50%. In that case, we might write:
\[ P(Y = y) = \begin{cases} \rho_H &\text{for }y= \text{Heads}\\ \rho_T &\text{for }y= \text{Tails} \end{cases}\]
Yet, we know that, by definition, \(\rho_H + \rho_T = 1\), so we can rewrite the above as:
\[ P(Y = y) = \begin{cases} \rho_H &\text{for }y= \text{Heads}\\ 1- \rho_H &\text{for }y= \text{Tails} \end{cases}\]
Coin flipping (and related scenarios with only two possible outcomes) are such common problems that the notation is often simplified further, with \(\rho\) understood, by convention, to be the probability of heads (or TRUE). In that case, we can write the mathematical distribution is two canonical forms:
\[P(Y) = Bernoulli(\rho)\] and
\[y_i \sim Bernoulli(\rho)\] All five of these versions mean the same thing! The first four describe the mathematical probability distribution for a fair coin. The capital \(Y\) within the \(P()\) indicates a random variable. The fifth highlights one “draw” from that random variable, hence the lower case \(y\) and the subscript \(i\).
Most probability distributions do not have special names, which is why we will use the generic symbol \(P\) to refer to them. But some common probability distributions do have names, like “Bernoulli” in this case.
If the mathematical assumptions are correct, then, as your sample size increases, the empirical probability distribution will look more and more like the mathematical distribution.
A posterior distribution is based on beliefs and expectations. It displays your beliefs about things you can’t see right now. You may have posterior distributions for outcomes in the past, present, or future.
In the case of the coin toss, the posterior distribution changes depending on your beliefs. For instance, let’s say your friend brought a coin to school and asked to bet you. If the result is heads, you have to pay them $5. In that case, your posterior probability distribution might look like this:
Show the code
# Hard-code the creation of the posterior.
tibble(results = c(rep(0, 95),
rep(1, 5))) |>
ggplot(aes(x = results)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 0.5,
color = "white") +
labs(title = "Posterior Probability Distribution",
subtitle = "Your beliefs about flipping one coin to bet your friend",
x = "Outcome\nResult of Coin Flip",
y = "Probability") +
scale_x_continuous(breaks = c(0, 1),
labels = c("Heads", "Tails")) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()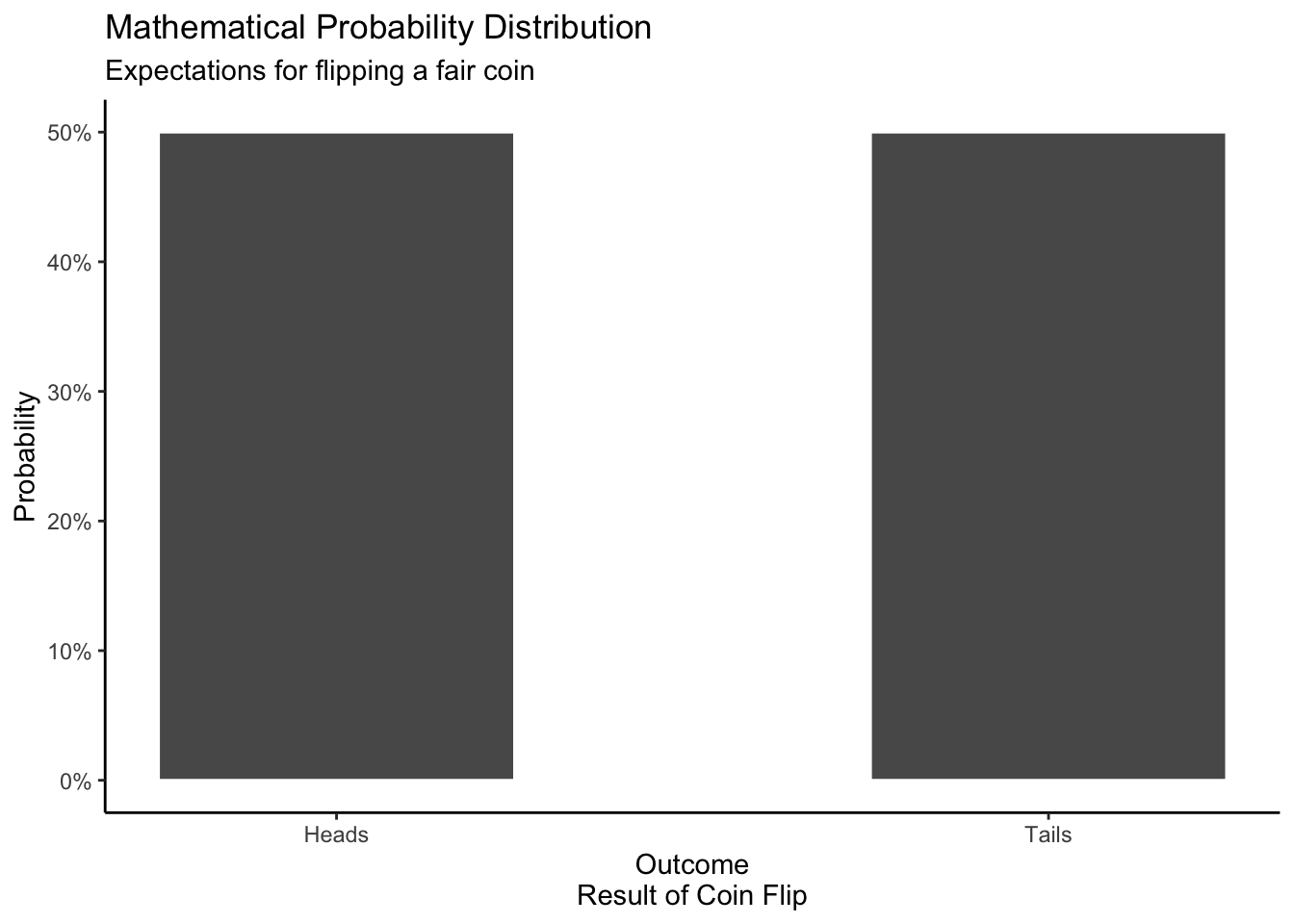
The fact that your friend wants to bet on heads suggests to you that the coin is not fair. Does it prove that the coin is unfair? No! Much depends on the sort of person you think your friend is. Your posterior probability distribution is your opinion, based on your experiences and beliefs. My posterior probability distribution will often be (very) different from yours.
The full terminology is mathematical (or empirical or posterior) probability distribution. But we will often shorten this to just mathematical (or empirical or posterior) distribution. The word “probability” is understood, even if it is not present.
Recall the question with which we started this section: What are the chances of getting three heads in a row when flipping a fair coin? To answer this question, we need to use a probability distribution as our data generating mechanism. Fortunately, the rbinom() function allows us to generate the results for coin flips. For example:
Show the code
rbinom(n = 10, size = 1, prob = 0.5) [1] 1 1 0 1 1 0 0 0 0 0generates the results of 10 coin flips, where a result of heads is presented as 1 and tails as 0. With this tool, we can generate 1,000 draws from our experiment:
Show the code
# A tibble: 1,000 × 3
toss_1 toss_2 toss_3
<int> <int> <int>
1 0 1 1
2 0 1 1
3 0 1 0
4 0 0 1
5 1 1 0
6 1 0 1
7 1 0 0
8 1 0 1
9 0 0 1
10 0 1 1
# ℹ 990 more rowsBecause the flips are independent, we can consider each row to be a draw from the experiment. Then, we simply count up the proportion of experiments in which resulted in three heads.
Show the code
# A tibble: 1 × 1
chance
<dbl>
1 0.104This is close to the “correct” answer of \(1/8\)th. If we increase the number of draws, we will get closer to the “truth.” The reason for the quotation marks around “correct” and “truth” is that we are uncertain. We don’t know the true probability distribution for this coin. If this coin is a trick coin — like the one we expect our friend to have brought to school — then the odds of three heads in a row would be much higher:
Show the code
# A tibble: 1 × 1
chance
<dbl>
1 0.87This is our first example of using a data generating mechanism — meaning rbinom() — to answer a question. We will see many more in the chapters to come.
2.2.2 Rolling two dice
Data science begins with a question:
What is the probability of rolling a 7 or an 11 with a pair of dice?
We get an empirical distribution by rolling two dice a hundred times, either by hand or with a computer simulation. The result is not identical to the mathematical distribution because of the inherent randomness of the real world and/or of simulation.
Show the code
# In the coin example, we create the vector ahead of time, and then assigned
# that vector to a tibble. There was nothing wrong with that approach. And we
# could do the same thing here. But the use of map_* functions is more powerful,
# although it requires creating the 100 rows of the tibble at the start and then
# doing things "row-by_row."
set.seed(1)
emp_dist_dice <- tibble(ID = 1:100) |>
mutate(die_1 = map_dbl(ID, ~ sample(c(1:6), size = 1))) |>
mutate(die_2 = map_dbl(ID, ~ sample(c(1:6), size = 1))) |>
mutate(sum = die_1 + die_2) |>
ggplot(aes(x = sum)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white") +
labs(title = "Empirical Probability Distribution",
subtitle = "Sum from rolling two dice, replicated one hundred times",
x = "Outcome\nSum of Two Dice",
y = "Probability") +
scale_x_continuous(breaks = seq(2, 12, 1), labels = 2:12) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
theme_classic()
emp_dist_dice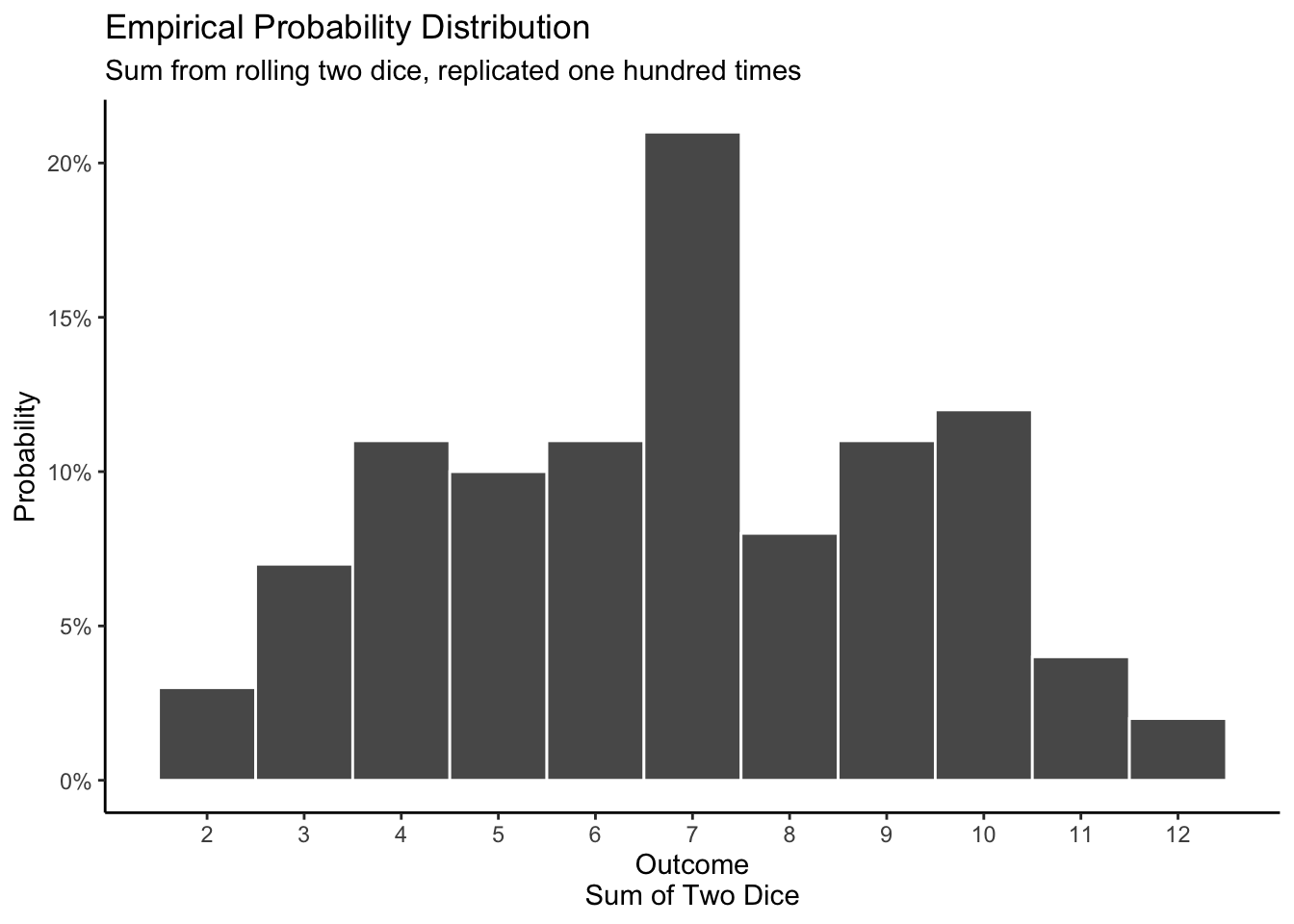
We might consider labeling the y-axis in plots of empirical distributions as “Proportion” rather than “Probability” since it is an actual proportion, calculated from real (or simulated) data. We will keep it as “Probability” since we want to emphasize the parallels between mathematical, empirical and posterior probability distributions.
Our mathematical distribution tells us that, with a fair dice, the probability of getting 1, 2, 3, 4, 5, and 6 are equal: there is a 1/6 chance of each. When we roll two dice at the same time and sum the numbers, the values closest to the middle are more common than values at the edge because there are more combinations of numbers that add up to the middle values.
Show the code
tibble(sum = c(rep(c(2, 12), 1),
rep(c(3, 11), 2),
rep(c(4, 10), 3),
rep(c(5, 9), 4),
rep(c(6, 8), 5),
rep(c(7), 6))) |>
ggplot(aes(x = sum)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white") +
labs(title = "Mathematical Probability Distribution",
subtitle = "Expectation for the sum from rolling two dice",
x = "Outcome\nSum of Two Dice",
y = "Probability") +
scale_x_continuous(breaks = seq(2, 12, 1), labels = 2:12) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()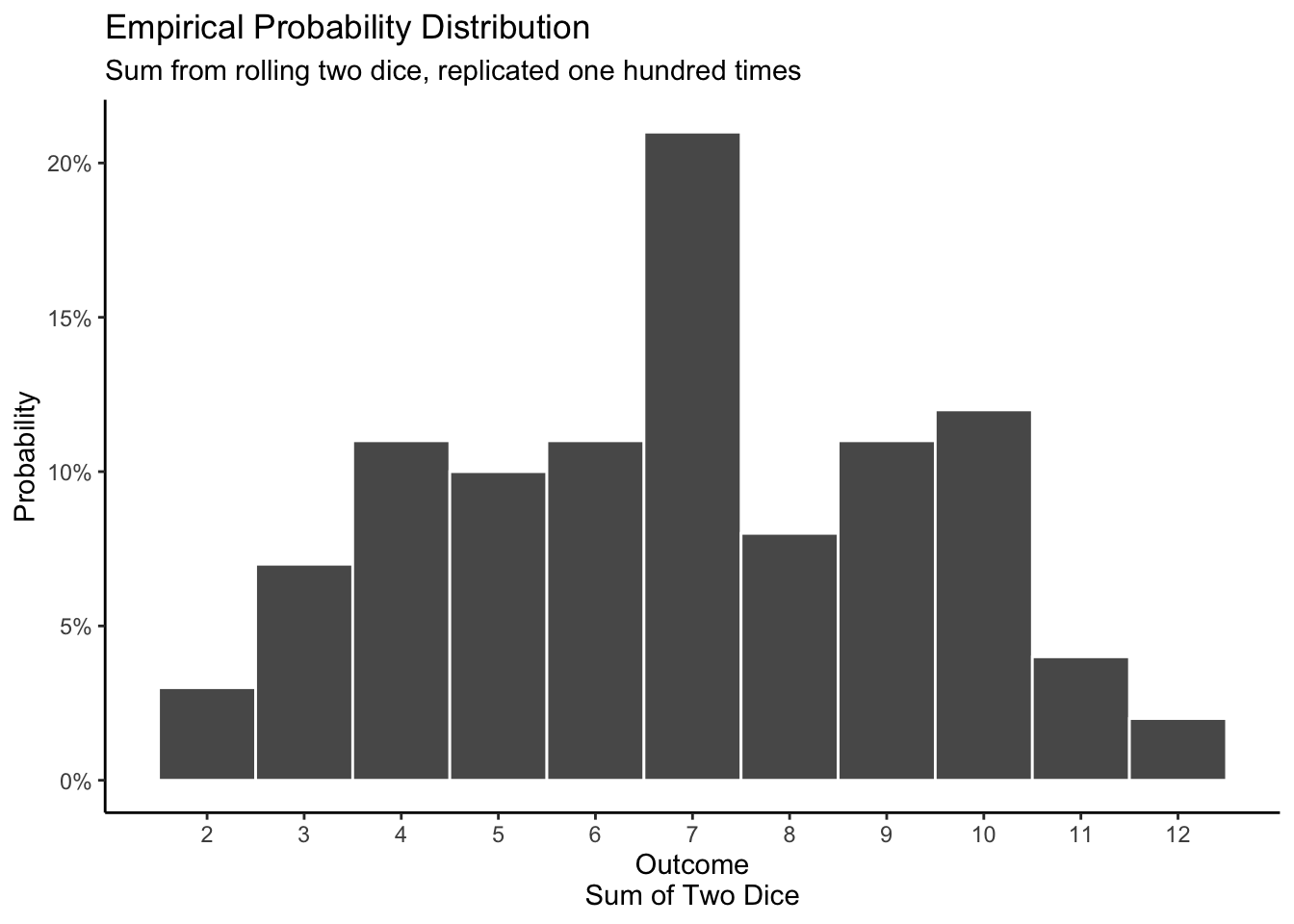
\[ P(Y = y) = \begin{cases} \dfrac{y-1}{36} &\text{for }y=1,2,3,4,5,6 \\ \dfrac{13-y}{36} &\text{for }y=7,8,9,10,11,12 \\ 0 &\text{otherwise} \end{cases} \]
The posterior distribution for rolling two dice depends on your beliefs. If you take the dice from your Monopoly set, you have reason to believe that the assumptions underlying the mathematical distribution are true. However, if you walk into a crooked casino and a host asks you to play craps, you might be suspicious, meaning that you suspect that the data generating mechanism for these dice is not like that for fair dice. For example, in craps, a “come-out” roll of 7 and 11 is a “natural,” resulting in a win for the “shooter” and, therefore, a loss for the casino. You might expect those numbers to occur less often than they would with fair dice. Meanwhile, a come-out roll of 2, 3 or 12 is a loss for the shooter. You might also expect values like 2, 3 and 12 to occur more frequently. Your posterior distribution might look like this:
Show the code
# Hard code our posterior about the crooked casino.
tibble(results = c(rep(2, 15), rep(3, 15), rep(4, 7),
rep(5, 7), rep(6, 7), rep(7, 4),
rep(8, 7), rep(9, 7), rep(10, 7),
rep(11, 3), rep(12, 15))) |>
ggplot(aes(x = results)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white") +
labs(title = "Posterior Probability Distribution",
subtitle = "Your belief about the sum of two dice at a crooked casino",
x = "Outcome\nSum of Two Dice",
y = "Probability") +
scale_x_continuous(breaks = seq(2, 12, 1), labels = 2:12) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()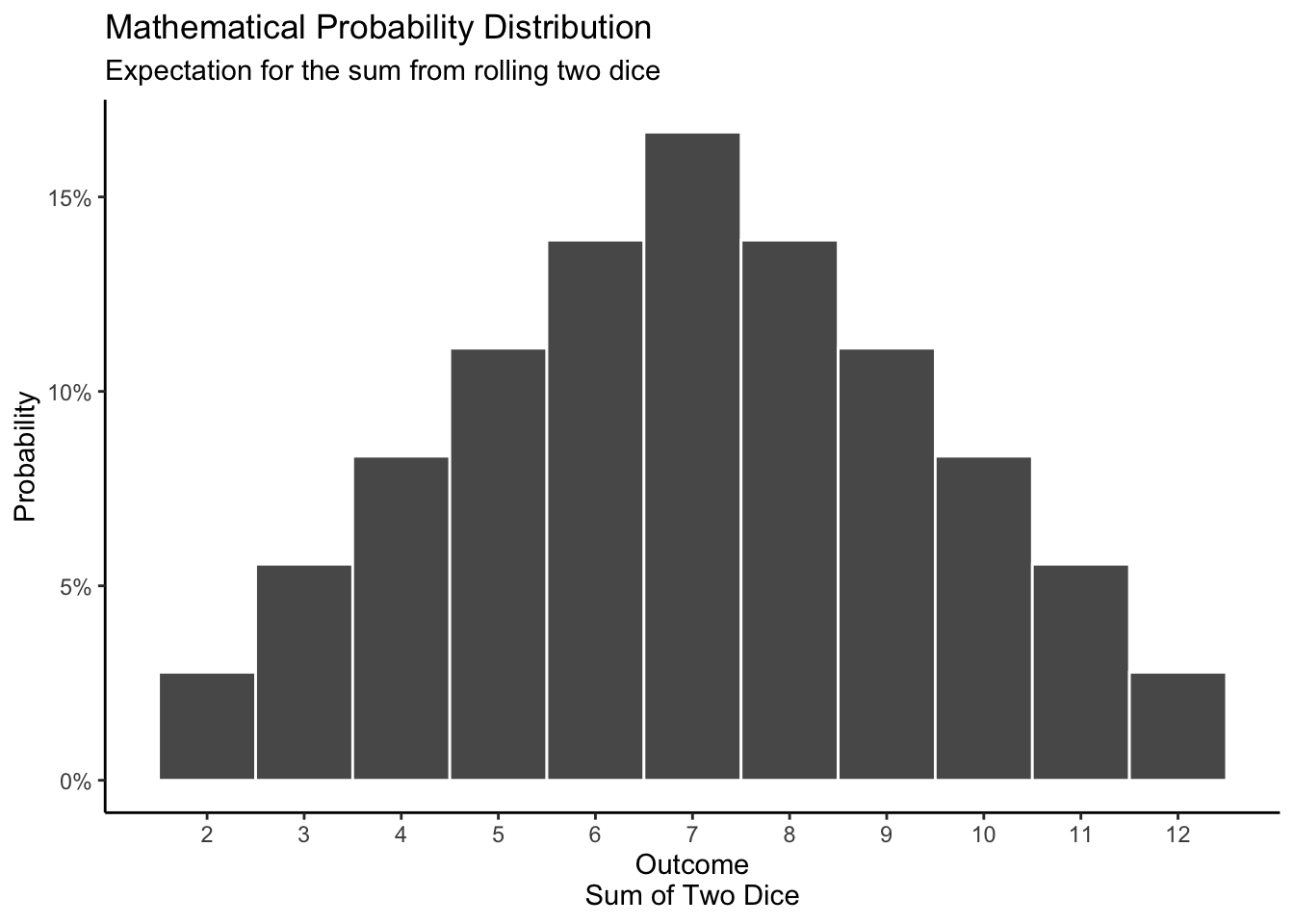
Someone less suspicious of the casino would have a posterior distribution which looks more like the mathematical distribution.
We began this section with a question about the probability (or odds) of rolling a 7 or 11 — i.e., a “natural” — with a pair of dice. The answer to the question depends on whether or not we think the dice are fair. In other words, we need to know which distribution to use to answer the question.
Assume that the dice are fair. In that case, we can create a data generating mechanism by hand. (Alas, there is not a built-in R function for dice like there is for coin flips with rbinom().)
Show the code
set.seed(7)
# Creating a variable like rolls makes our code easier to read and modify. Of
# course, we could just hard code the 4 into the size argument for each of the
# two calls to sample, but that is much less convenient.
rolls <- 4
# The details of the code matter. If we don't have replace = TRUE, sample will
# only use each of the 6 possible values once. That might be OK if we are just
# rolling the dice 4 times, but it won't work for thousands of rolls.
tibble(dice_1 = sample(x = 1:6, size = rolls, replace = TRUE),
dice_2 = sample(x = 1:6, size = rolls, replace = TRUE)) |>
mutate(result = dice_1 + dice_2) |>
mutate(natural = ifelse(result %in% c(7, 11), TRUE, FALSE))# A tibble: 4 × 4
dice_1 dice_2 result natural
<int> <int> <int> <lgl>
1 2 2 4 FALSE
2 3 6 9 FALSE
3 4 3 7 TRUE
4 2 6 8 FALSE This code is another data generating mechanism or DGM. It allows us to simulate the distribution of the results from rolling a pair of fair dice. To answer our question, we simply increase the number of rolls and calculate the proportion of rolls which result in a 7 or 11.
Show the code
rolls <- 100000
# We probably don't need 100,000 rolls, but this code is so fast that it does
# not matter. Generally 1,000 (or even 100) draws from the data generating
# mechanism is enough for most practical purposes.
tibble(dice_1 = sample(x = 1:6, size = rolls, replace = TRUE),
dice_2 = sample(x = 1:6, size = rolls, replace = TRUE)) |>
mutate(result = dice_1 + dice_2) |>
summarize(natural_perc = mean(result %in% c(7, 11)))# A tibble: 1 × 1
natural_perc
<dbl>
1 0.221The probability of rolling either a 7 or an 11 with a pair of fair dice is about 22%.
2.2.3 Presidential elections
Data science begins with a question:
What is the probability that the Democratic candidate will win the Presidential election?
Consider the probability distribution for a political event, like a presidential election. We want to know the probability that Democratic candidate wins X electoral votes, where X comes from the range of possible outcomes: 0 to 538. (The total number of electoral votes in US elections since 1964 is 538.)
The empirical distribution in this case would involve counting the number of electoral votes that the Democratic candidate won in each of the Presidential elections in the last 50 years or so. Looking at elections since 1964, we can observe that the number of electoral votes that the Democratic candidate received in each election is different.
Show the code
# Votes are since 1964, for Democratic candidate
mydata <- tibble(electoral_votes = c(486, 191, 17, 297, 49, 13, 111,
370, 379, 266, 251, 365, 332,
227, 306, 226))
# 226 is electoral votes for Joe Biden in 2024 presidential election.
ggplot(mydata, aes(x = electoral_votes)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
bins = 100,
color = "white") +
labs(title = "Empirical Probability Distribution",
subtitle = "Electoral votes from 16 previous elections",
x = "Outcome\nElectoral Vote Total for Democratic Candidate",
y = "Probability") +
scale_x_continuous(breaks = seq(0, 500, 100)) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()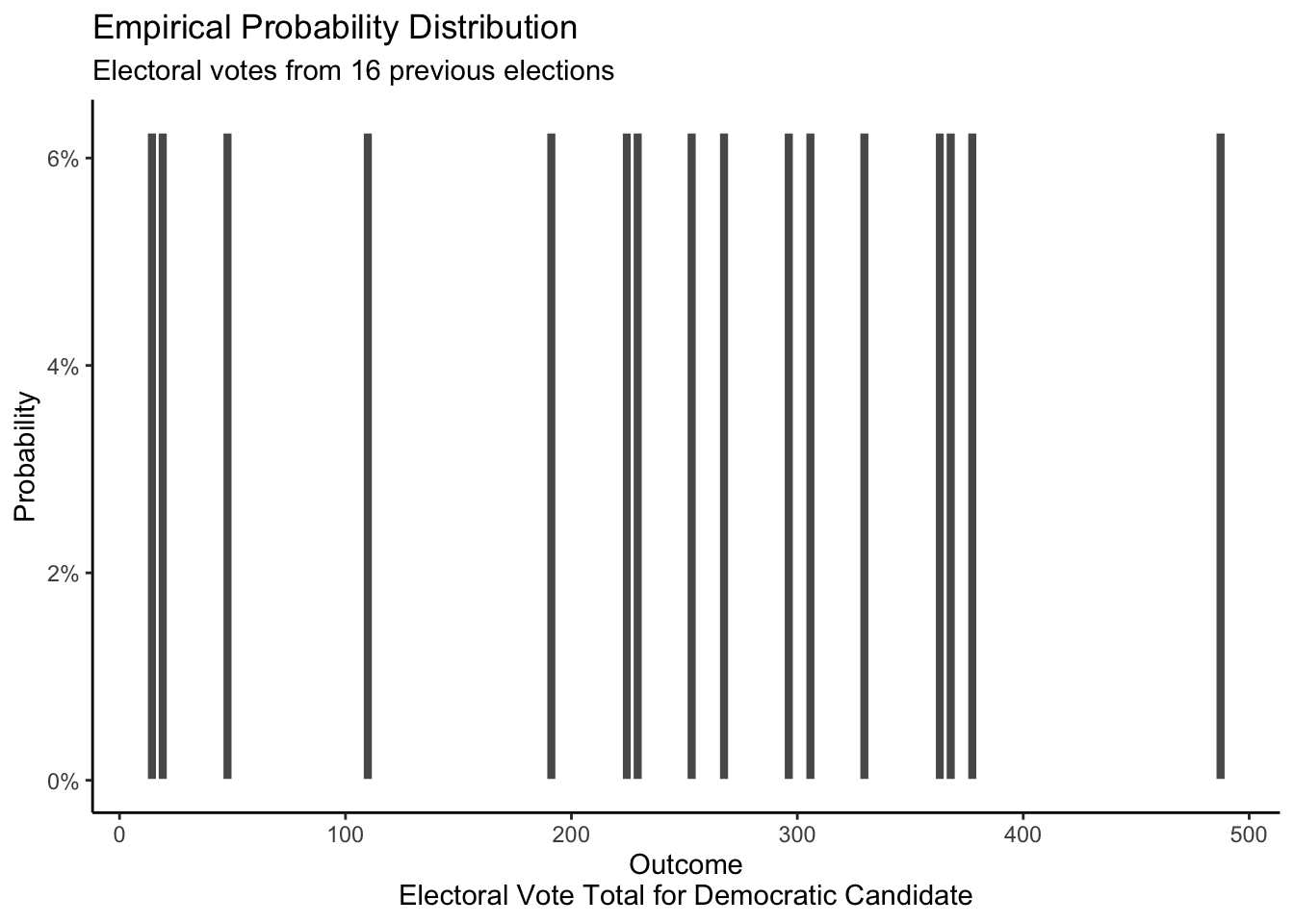
Given that we only have 15 observations, it is difficult to draw conclusions or make predictions based off of this empirical distribution. But “difficult” does not mean “impossible.” For example, if someone, more than a year before the election, offered to bet us 50/50 that the Democratic candidate was going to win more than 475 electoral votes, we would take the bet. After all, this outcome has only happened once in the last 15 elections, so a 50/50 bet seems like a great deal.
We can build a mathematical distribution for X which assumes that the chances of the Democratic candidate winning any given state’s electoral votes is 0.5 and that the results from each state are independent.
Show the code
# Code currently produces a warning about missing values. Not sure why? Maybe an
# interaction with the hard-coded limits in the x-axis?
# We want the hard-coded limits because we want to make it obvious that the
# mathematical results suggest that outcomes < 100 or > 400 are essentially
# impossible. Text could make that more clear.
# rep(3,8) means there are 8 states that have 3 electoral votes, via the same
# for the rest of the code chunck. We use c() to make the rep() functions
# together, so that we can use it in tibble().
# I think these electoral votes are for 2016. Probably should update them for post 2020 census.
ev <- c(rep(3, 8), rep(4, 5), rep(5, 3), rep(6, 6), rep(7, 3), rep(8,2),
rep(9, 3), rep(10, 4), rep(11, 4), 12, 13, 14, 15, rep(16, 2), 18, 20 , 20, 19, 29, 38, 55)
sims <- 10000
result <- tibble(total = (matrix(rbinom(sims*length(ev),
size = 1, p = 0.5),
ncol = length(ev)) %*% ev)[,1])
ggplot(data = result, aes(total)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1) +
labs(title = "Mathematical Probability Distribution",
subtitle = "Presidential elections with each state being 50/50 and independent",
y = "Probability",
x = "Outcome\nElectoral Vote Total for Democratic Candidate") +
scale_x_continuous(breaks = seq(0, 500, 100), limits = c(0, 540)) +
scale_y_continuous(labels =
scales::percent_format()) +
theme_classic()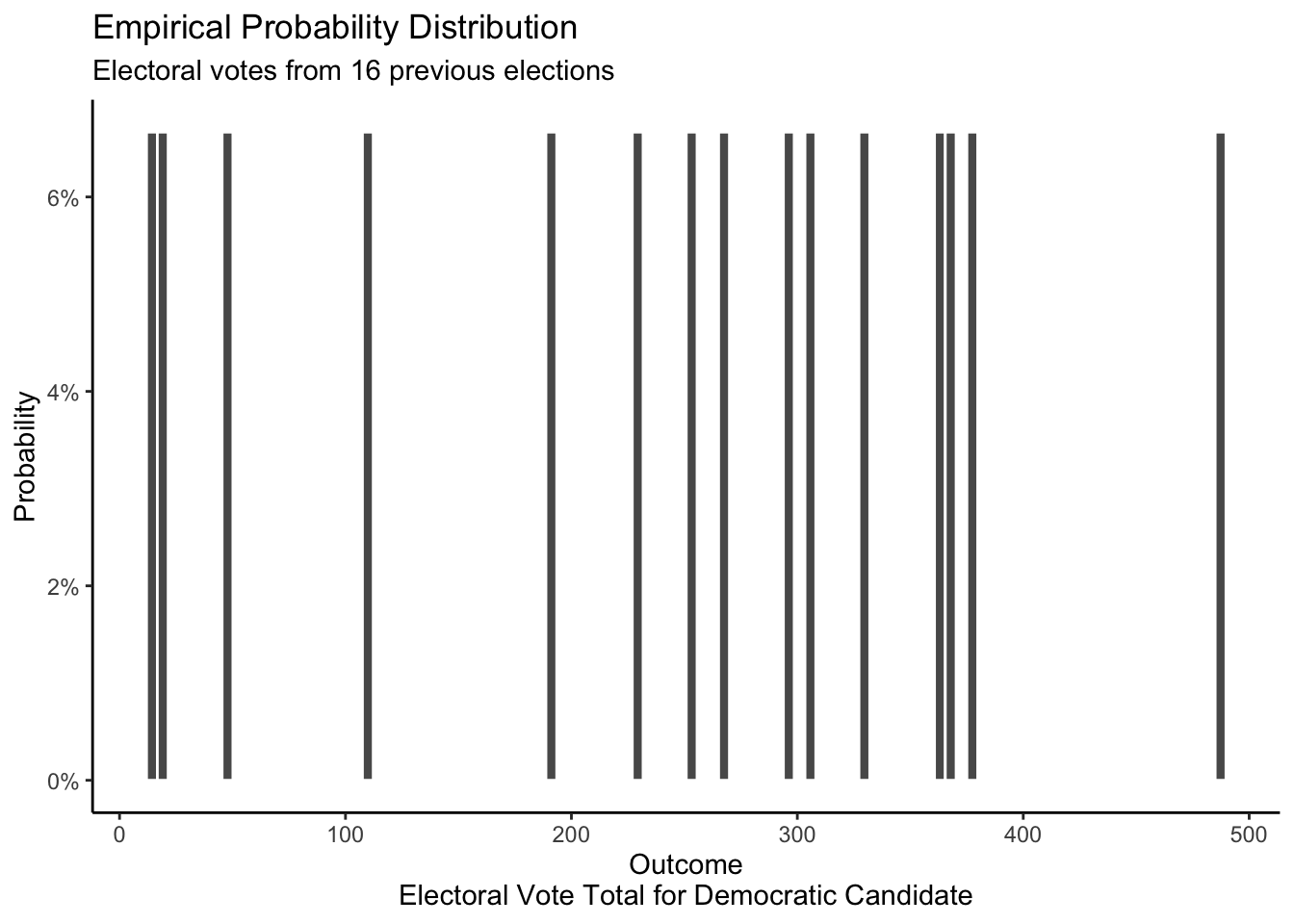
If our assumptions about this mathematical distribution are correct — they are not! — then, as the sample size increase, the empirical distribution should look more and more similar to our mathematical distribution.
However, the data from past elections is more than enough to demonstrate that the assumptions of our mathematical probability distribution do not work for electoral votes. The model assumes that the Democrats have a 50% chance of receiving each of the total electoral votes from the 50 states and the District of Columbia. Just looking at the mathematical probability distribution, we can observe that receiving 13 or 17 or 486 votes out of 538 would be extreme and almost impossible if the mathematical model were accurate. However, our empirical distribution shows that such extreme outcomes are quite common. Presidential elections have resulted in much bigger victories or defeats than this mathematical distribution seems to allow for, thereby demonstrating that our assumptions are false.
The posterior distribution of electoral votes is a popular topic, and an area of strong disagreement, among data scientists. Consider this posterior from FiveThirtyEight.
Show the code
# This data was downloaded by hand from the 538 website.
# Have to include these cols type, otherwise it will shows up this "Column
# specification", thing on the primer, not pretty.
read_csv("./probability/data/election-forecasts-2020/prez_1.csv",
col_types = cols(cycle = col_double(),
branch = col_character(),
model = col_character(),
modeldate = col_character(),
candidate_inc = col_character(),
candidate_chal = col_character(),
candidate_3rd = col_logical(),
evprob_inc = col_double(),
evprob_chal = col_double(),
evprob_3rd = col_logical(),
total_ev = col_double(),
timestamp = col_character(),
simulations = col_double())) |>
select(evprob_chal, total_ev) |>
rename(prob = evprob_chal, electoral_votes = total_ev) |>
ggplot(aes(electoral_votes, prob)) +
geom_bar(stat = 'identity') +
labs(title = "Posterior Probability Distribution",
subtitle = "Democratic electoral votes according to 538 forecast",
y = "Probability",
x = "Outcome\nElectoral Vote Total for Democratic Candidate",
caption = "Data from August 13, 2020") +
scale_y_continuous(breaks = c(0, 0.01, 0.02),
labels =
scales::percent_format(accuracy = 1)) +
theme_classic()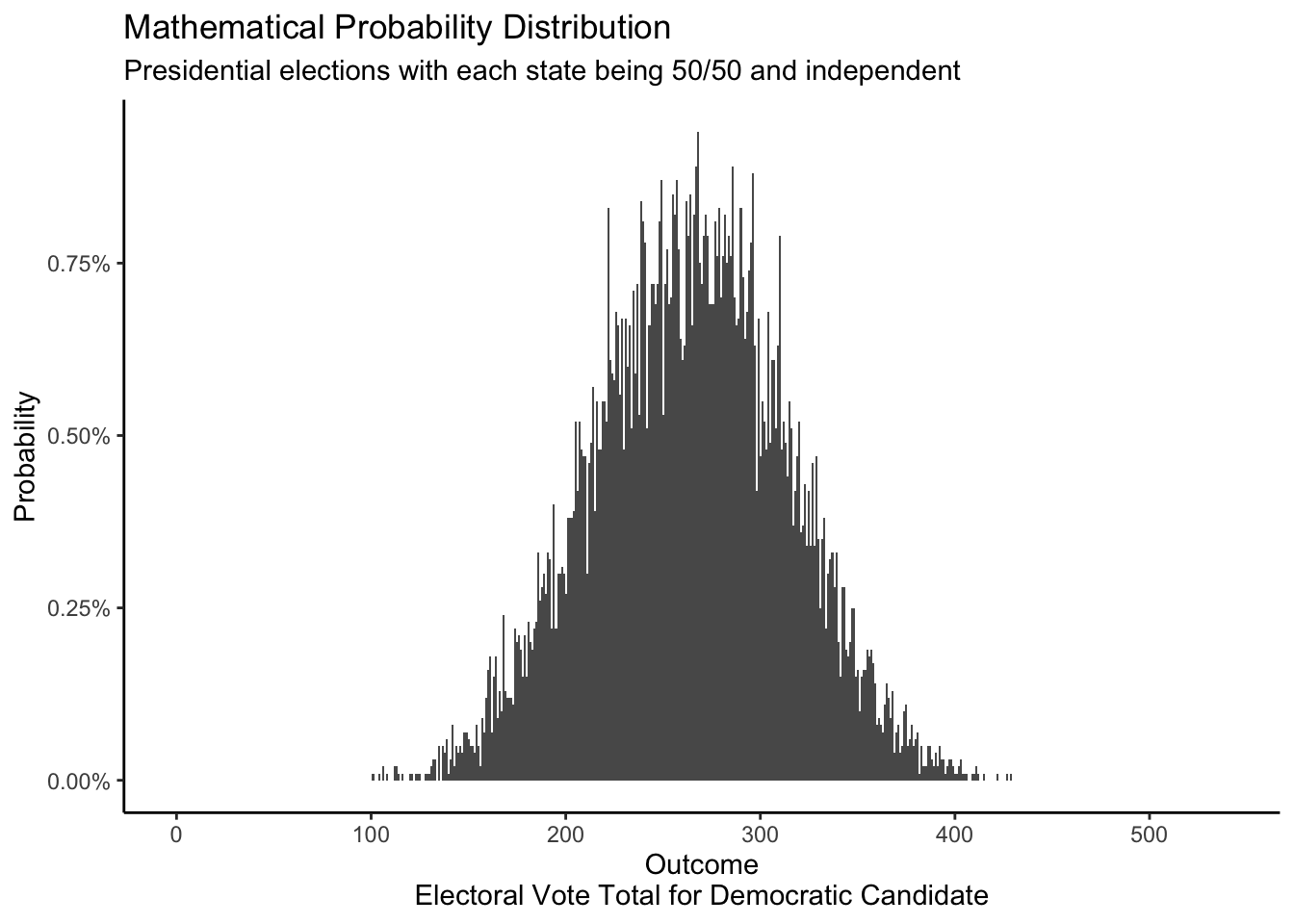
Below is a posterior probability distribution from the FiveThirtyEight website for August 13, 2020. This was created using the same data as the above distribution, but is displayed differently. For each electoral result, the height of the bar represents the probability that a given event will occur. However, there are no labels on the y-axis telling us what the specific probability of each outcome is. And that is OK! The specific values are not that useful. If we removed the labels on our own y-axes, would it matter? Probably not. Anytime there are many possible outcomes — over 500 in this case — we stop looking at specific outcomes and, instead, look at where most of the “mass” of the distribution lies.
Show the code
knitr::include_graphics("probability/images/fivethirtyeight.png")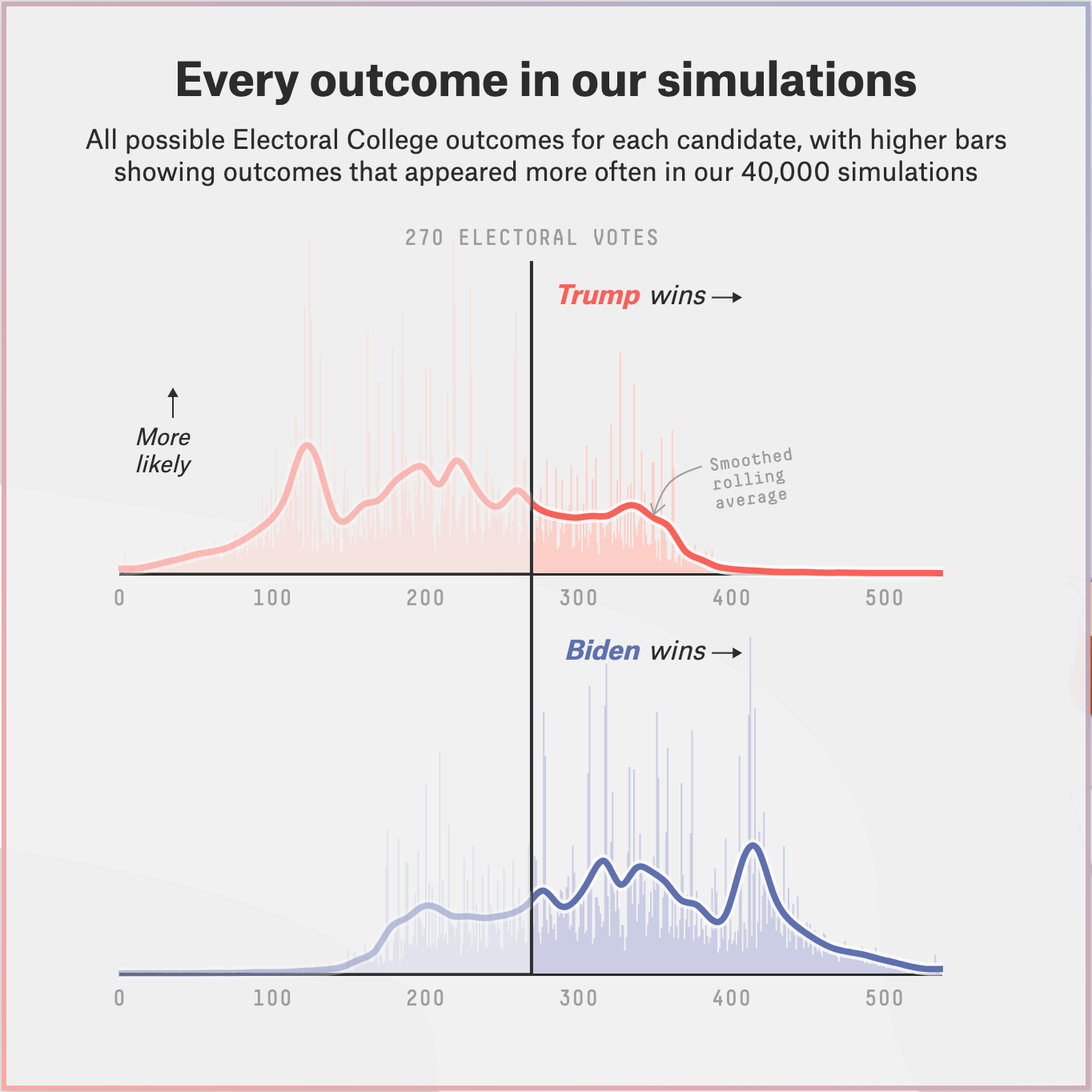
Below is the posterior probability distribution from The Economist, also from August 13, 2020. This looks confusing at first because they chose to combine the axes for Republican and Democratic electoral votes. The Economist was less optimistic, relative to FiveThirtyEight, about Trump’s chances in the election.
Show the code
knitr::include_graphics("probability/images/economist_aug13.png")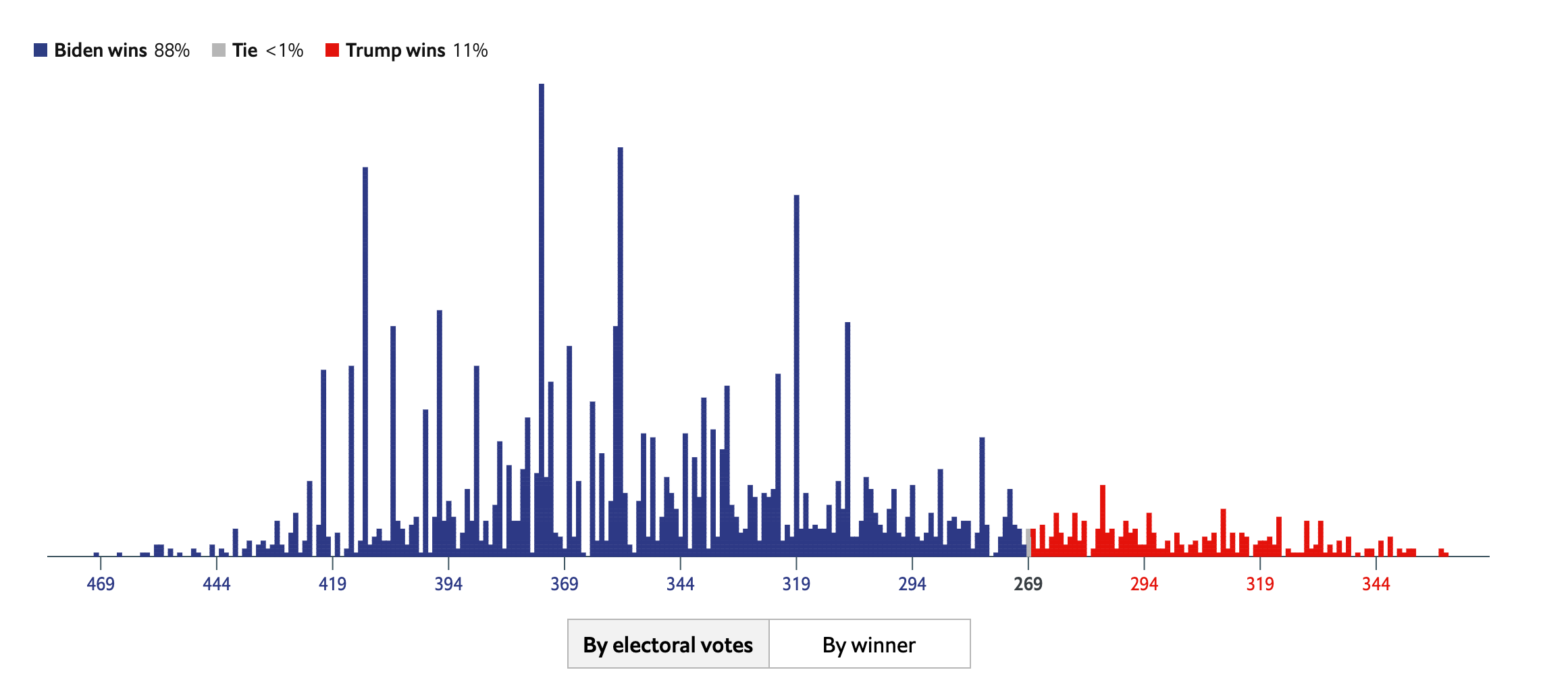
These two models, built by smart people using similar data sources, have reached fairly different conclusions. Data science is difficult! There is not one “right” answer. Real life is not a problem set.
Show the code
knitr::include_graphics("probability/images/538_versus_Economist.png")
There are many questions you could explore with posterior distributions. They can relate to the past, present, or future.
- Past: How many electoral votes would Hilary Clinton have won if she had picked a different VP?
- Present: What are the total campaign donations from New College faculty?
- Future: How many electoral votes will the Democratic candidate for president win in 2036?
2.2.4 Height
Question: What is the height of the next adult male we will meet?
The three examples above are all discrete probability distributions, meaning that the outcome variable can only take on a limited set of values. A coin flip has two outcomes. The sum of a pair of dice has 11 outcomes. The total electoral votes for the Democratic candidate has 539 possible outcomes. In the limit, we can also create continuous probability distributions which have an infinite number of possible outcomes. For example, the average height for an American male could be any real number between 0 inches and 100 inches. (Of course, a value anywhere near 0 or 100 is absurd. The point is that the average could be 68.564, 68.5643, 68.56432 68.564327, or any real number.)
All the characteristics for discrete probability distributions which we reviewed above apply just as much to continuous probability distributions. For example, we can create mathematical, empirical and posterior probability distributions for continuous outcomes just as we did for discrete outcomes.
The empirical distribution involves using data from the National Health and Nutrition Examination Survey (NHANES).
Show the code
# Use nhanes data set for this exercise, filter for adult and male.
nhanes |>
filter(sex == "Male", age >= 18) |>
select(height)|>
drop_na() |>
ggplot(aes(x = height)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white")+
labs(title = "Empirical Probability Distribution",
subtitle = "Height for adult men",
x = "Height (cm)",
y = "Probability",caption = "Source:NHANES") +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()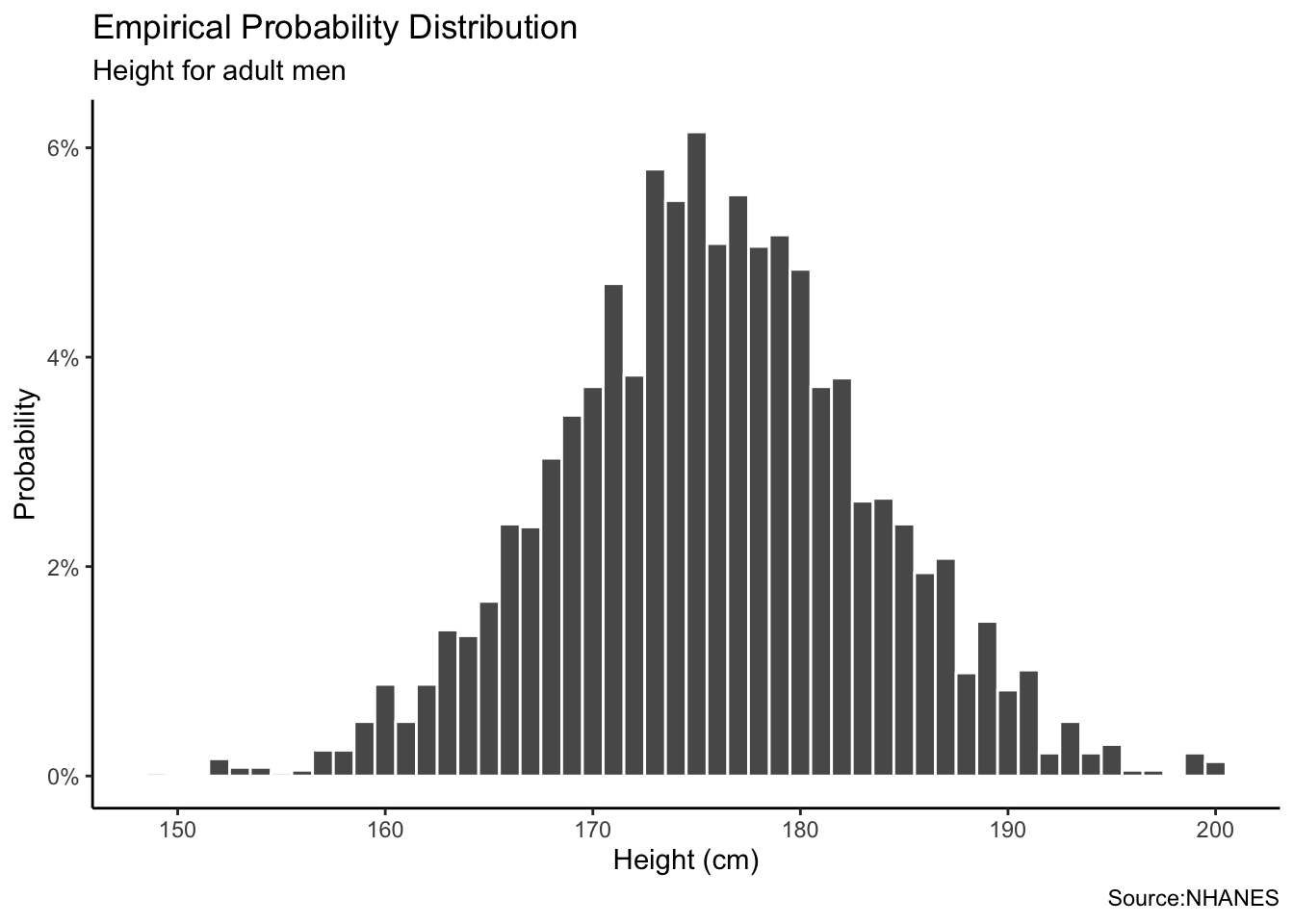
Mathematical distribution is completely based on mathematical formula and assumptions, as in the coin flip example. In the coin-flip example, we assumed that the coin was perfectly fair, meaning that the probability of landing on heads or tails was equal. In this case, we make three assumptions. First, a male height follows a Normal distribution. Second, the average height of men is 175 cm. Third, the standard deviation for male height is 9 cm. We can create a Normal distribution using the rnorm() function with these two parameter values.
Show the code
# Greater the n size, the smoother the graph. Shouldn't we use geom_density?
tibble(height = rnorm(1000000, mean = 175, sd = 9)) |>
ggplot(aes(x = height)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white")+
labs(title = "Mathematical Probability Distribution",
subtitle = "Male height assuming a normal distribution with a mean of 175 cm and sd of 9 cm",
x = "Height (cm)",
y = "Probability") +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()
Again, the Normal distribution which is a probability distribution that is symmetric about the mean described by this formula.
\[y_i \sim N(\mu, \sigma^2)\]
Each value \(y_i\) is drawn from a Normal distribution with parameters \(\mu\) for the mean and \(\sigma\) for the standard deviation. If the assumptions are correct, then, as our sample size increases, the empirical probability distribution will look more and more like the mathematical distribution.
The posterior distribution for heights depends on the context. Are we considering all the adult men in America? In that case, our posterior would probably look a lot like the empirical distribution using NHANES data. If we are being asked about the distribution of heights among players in the NBA, then our posterior might look like:
Show the code
tibble(height = rnorm(100000, 200, 6)) |>
ggplot(aes(x = height)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white")+
labs(title = "Posterior Probability Distribution",
subtitle = "My belief about the heights of professional basketball players",
x = "Height (cm)",
y = "Probability") +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()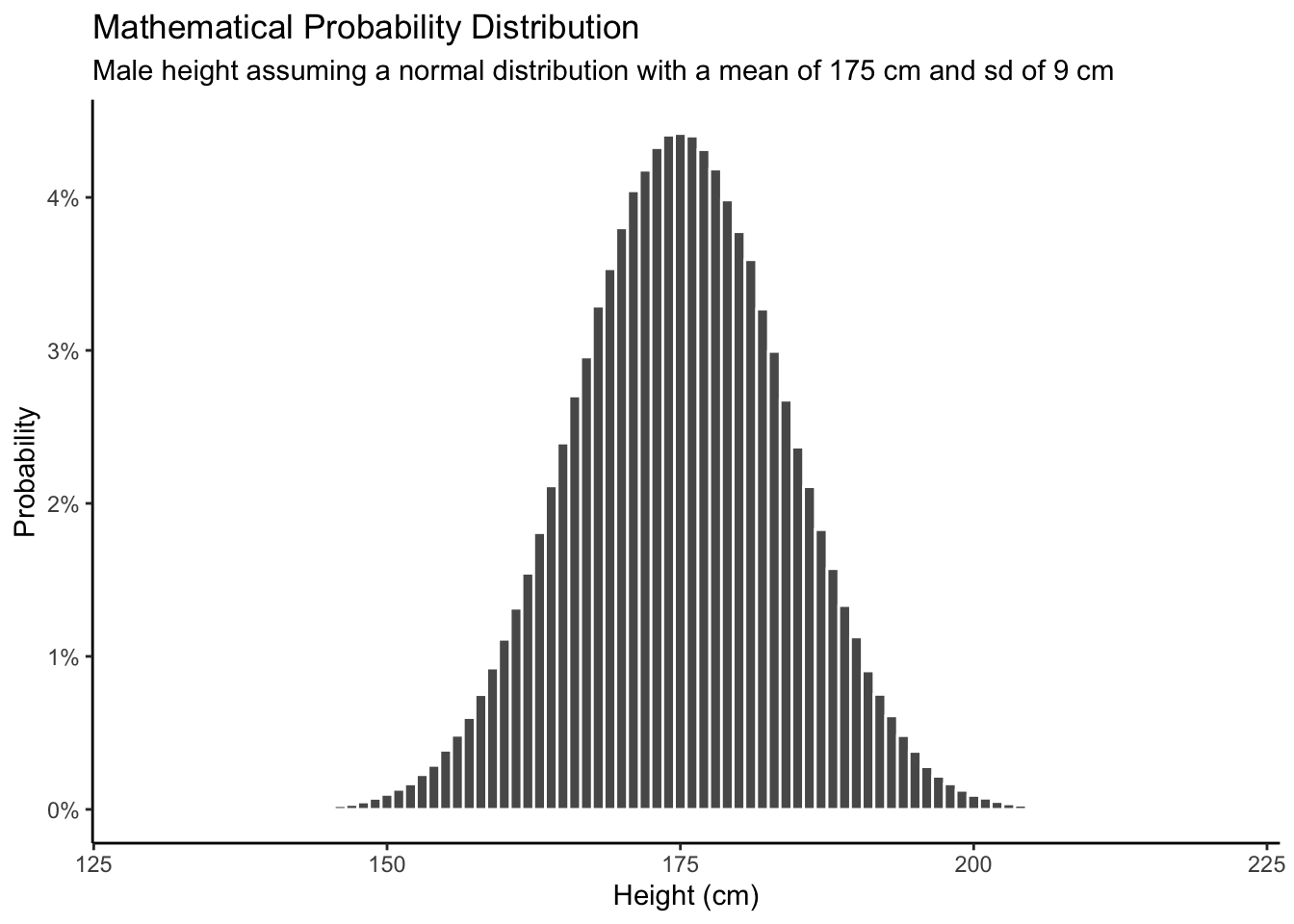
Caveats:
Continuous variables are a myth. Nothing that can be represented on a computer is truly continuous. Even something which appears continuous, like height, actually can only take on a (very large) set of discrete variables.
The math of continuous probability distributions can be tricky. Read a book on mathematical probability for all the messy details. Little of that matters in applied work.
The most important difference is that, with discrete distributions, it makes sense to estimate the probability of a specific outcome. What is the probability of rolling a 9? With continuous distributions, this makes no sense because there are an infinite number of possible outcomes. With continuous variables, we only estimate intervals.
Don’t worry about the distinctions between discrete and continuous outcomes, or between the discrete and continuous probability distributions which we will use to summarize our beliefs about those outcomes. The basic intuition is the same in both cases.
2.2.5 Joint distributions
Recall that \(P(\text{coin})\) is the probability distribution for the result of a coin toss. It includes two parts, the probability of heads (\(\rho_h\)) and the probability of tails (\(\rho_t\)). This is a univariate distribution because there is only one outcome, which can be heads or tails. If there is more than one outcome, then we have a joint distribution.
Joint distributions are also mathematical objects that cover a set of outcomes, where each distinct outcome has a chance of occurring between 0 and 1 and the sum of all chances must equal 1. The key to a joint distribution is that it measures the chance that both outcome \(a\) from the set of events A and outcome \(b\) from the set of events B will occur. The notation is \(P(A, B)\).
Let’s say that you are rolling two six-sided dice simultaneously. Dice 1 is weighted so that there is a 50% chance of rolling a 6 and a 10% chance of each of the other values. Dice 2 is weighted so there is a 50% chance of rolling a 5 and a 10% chance of rolling each of the other values. Let’s roll both dice 1,000 times. In previous examples involving two dice, we cared about the sum of results and not the outcomes of the first versus the second dice of each simulation. With a joint distributions, the outcomes for individual dice matter; so instead of 11 possible outcomes on the x-axis of our distribution plot (ranging from 2 to 12), we have 36 outcomes. Furthermore, a 2D probability distribution is not sufficient to represent all of the variables involved, so the joint distribution for this example is displayed using a 3D plot.
Show the code
# Revisit and clean up this code.
# Step 1: Create and organize the data.
mydata <- tibble(die.1 = sample(1:6, size = 1000, prob =
c(0.1, 0.1, 0.1, 0.1, 0.1, 0.5), replace = TRUE),
die.2 = sample(1:6, size = 1000, prob =
c(0.1, 0.1, 0.1, 0.1, 0.5, 0.1), replace = TRUE)) |>
summarize(total = n(),
.by = c(die.1, die.2))
die1_factor <- as.factor(mydata$die.1)
die2_factor <- as.factor(mydata$die.2)
# Step 2: Create a ggplot object.
mtplot <- ggplot(mydata) +
geom_point(aes(x = die1_factor, y = die2_factor, color = total)) +
scale_color_continuous(limits = c(0, 100)) +
labs(x = "Dice 1", y = "Dice 2") +
theme(legend.position = "none")
# Step 3: Turn it into a 3D plot. This takes a bit of time and
# will open an interactive "RGL Device" window with the plot.
plot_gg(mtplot,
width = 3.5, # Plot width
zoom = 0.65, # How close view on plot should be (1=normal, <1=closer)
theta = 25, # From which direction to view plot (0-360°)
phi = 30, # How "steep" view on plot should be (0-90°)
sunangle = 225, # Angle of sunshine for shadows (0-360°)
soliddepth = -0.5, # Thickness of pane (always <0, the smaller the thicker)
windowsize = c(2048,1536)) # Resolution
# Save the plot as an image
rgl::rgl.snapshot("probability/images/die.png")
# Close the RGL device
rgl::close3d()
2.2.6 Conditional distrubutions
Imagine that 60% of people in a community have a disease. A doctor develops a test to determine if a random person has the disease. However, this test isn’t 100% accurate. There is an 80% probability of correctly returning positive if the person has the disease and 90% probability of correctly returning negative if the person does not have the disease.
The probability of a random person having the disease is 0.6. Since each person either has the disease or doesn’t (those are the only two possibilities), the probability that a person does not have the disease is \(1 - 0.6 = 0.4\).
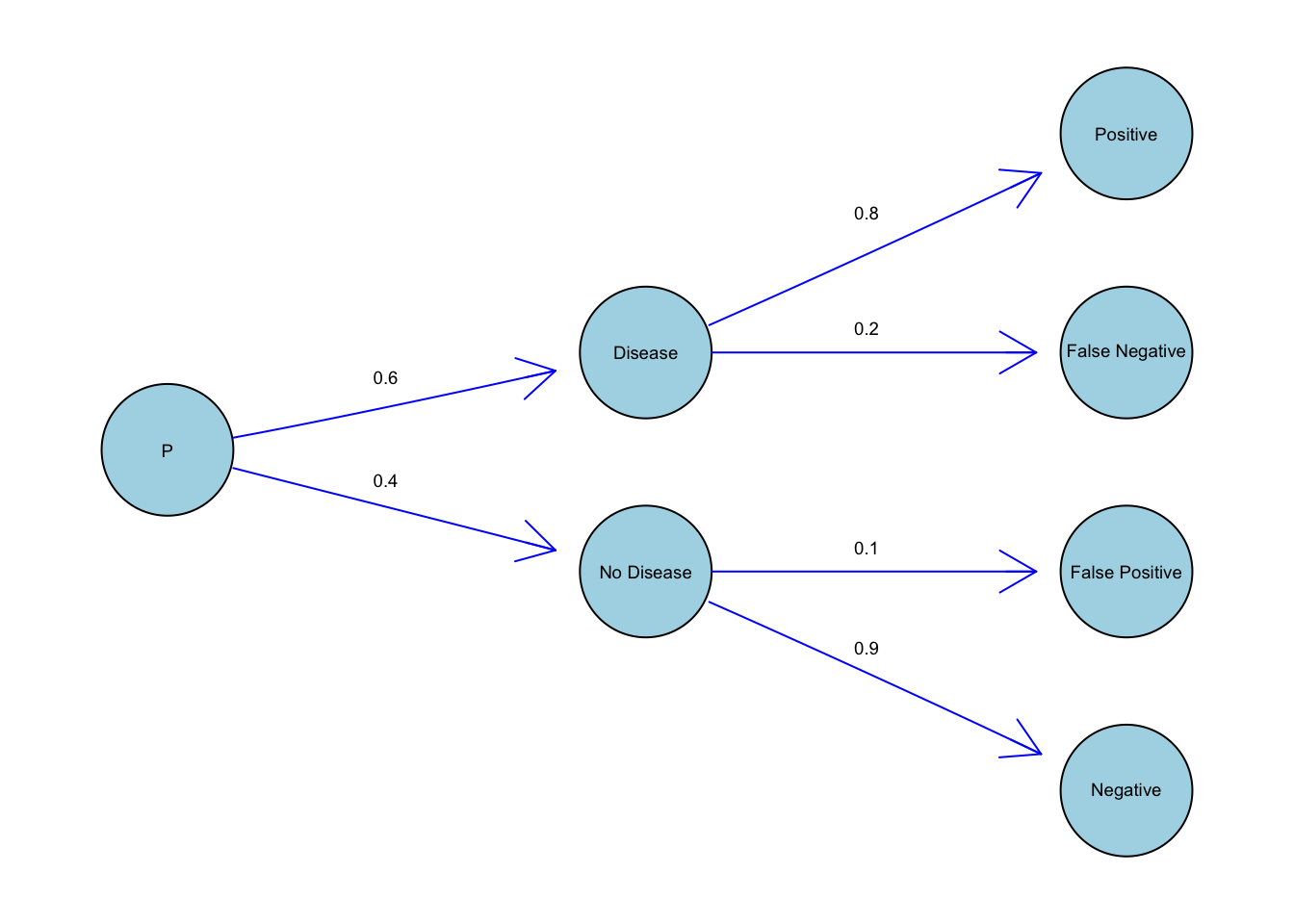
If a person has the disease, then we go up the top branch. The probability of an infected person testing positive is 0.8 because the test is 80% sure of correctly returning positive when the person has the disease.
By the same logic, if a person does not have the disease, we go down the bottom branch. The probability of the person incorrectly testing positive is 0.1.
We decide to go down the top branch if our random person has the disease. We go down the bottom branch if they do not. This is conditional probability. The probability of testing positive is dependent on whether the person has the disease.
How would you express this in statistical notation? \(P(A|B)\) is the same thing as the probability of A given B. \(P(A|B)\) means the probability of A if we know for sure the value of B. Note that \(P(A|B)\) is not the same thing as \(P(B|A)\).
There are three main categories of probability distributions: univariate, joint and condictional. \(p(A)\) is the probability distribution for event A. This is a univariate probability distribution because there is only one random variable. \(p(A, B)\) is the joint probability distribution of A and B. \(p(A | B)\) is the conditional probability distribution of A given that B has taken on a specific value. This is often written as \(p(A | B = b)\).
2.3 Two models
The simplest possible setting for inference involves two models — meaning two possible states of the world — and two outcomes from an experiment. Imagine that there is a disease — Probophobia, an irrational fear of probability — which you either have or don’t have. We don’t know if you have the diseases, but we do assume that there are only two possibilities.
We also have a test which is 99% accurate when given to a person who has Probophobia. Unfortunately, the test is only 50% accurate for people who do not have Probophobia. In this experiment, there only two possible outcomes: a positive and a negative result on the test.
Question: If you test positive, what is the probability that you have Probophobia?
More generally, we are estimating a conditional probability. Conditional on the outcome of a postive test, what is the probability that you have Probophobia? Mathematically, we want:
\[ P(\text{Probophobia | Test = Postive} ) \]
To answer this question, we need to use the tools of joint and conditional probability from earlier in the Chapter. We begin by building, by hand, the joint distribution of the possible models (you have the Probophobia or you do not) and of the possible outcomes (you test positive or negative). Building the joint distribution involves assuming that each model is true and then creating the distribution of outcomes which might occur if that assumption is true.
For example, assume you have Probophobia. There is then a 50% chance that you test positive and a 50% chance you test negative. Similarly, if we assume that the second model is true — that you don’t have Probophobia — then there is 1% chance you test positive and a 99% you chance negative. Of course, for you (or any individual) we do not know for sure what is happening. We do not know if you have the disease. We do not know what your test will show. But we can use these relationships to construct the joint distribution.
Show the code
set.seed(9)Show the code
# Pipes generally start with tibbles, so we start with a tibble which just
# includes an ID variable. We don't really use ID. It is just handy for getting
# organized. We call this object `jd_disease`, where the `jd` stands for
# joint distribution.
sims <- 10000
jd_disease <- tibble(ID = 1:sims, have_disease = rep(c(TRUE, FALSE), 5000)) |>
mutate(positive_test =
if_else(have_disease,
map_int(have_disease, ~ rbinom(n = 1, size = 1, p = 0.99)),
map_int(have_disease, ~ rbinom(n = 1, size = 1, p = 0.5))))
jd_disease# A tibble: 10,000 × 3
ID have_disease positive_test
<int> <lgl> <int>
1 1 TRUE 1
2 2 FALSE 1
3 3 TRUE 1
4 4 FALSE 1
5 5 TRUE 1
6 6 FALSE 0
7 7 TRUE 1
8 8 FALSE 1
9 9 TRUE 1
10 10 FALSE 0
# ℹ 9,990 more rowsThe first step is to simply create an tibble that consists of the simulated data we need to plot our distribution. Keep in mind that in the setting we have two different probabilities and they are completely separate from each other and we want to keep the two probabilities and the disease results in two and only two columns so that we can graph using the ggplot() function. And that’s why we used the rep and seq functions when creating the table, we used the seq function to set the sequence we want, which in this case is only two numbers, 0.01 (99% accuracy for testing negative if no disease, therefore 1% for testing positive if no disease) and 0.5 (50% accuracy for testing positive/negative if have disease), then we used the rep functions to repeat the process 10,000 times for each probability, in total 20,000 times. Note that this number “20,000” also represents the number of observations in our simulated data, we simulated 20,000 results from testing, where 10,000 results from the have-disease group and 10,000 for the no-disease group, we often use the capital N to represent the population, in this simulated data \(N=20,000\).
Plot the joint distribution:
Show the code
# Use discrete for FALSE and TRUE
jd_disease |>
ggplot(aes(x = as.factor(positive_test),
y = as.factor(have_disease))) +
geom_point() +
geom_jitter(alpha = .2) +
labs(title = "Unnormalized Distribution of Test Results and Disease Status",
subtitle = "Many False results in have disease than no disease",
x = "Test Result",
y = "Disease Status") +
scale_x_discrete(breaks = c(0, 1),
labels = c("Negative", "Positive")) +
scale_y_discrete(breaks = c(FALSE, TRUE),
labels = c("No Disease", "Have Disease")) +
theme_classic()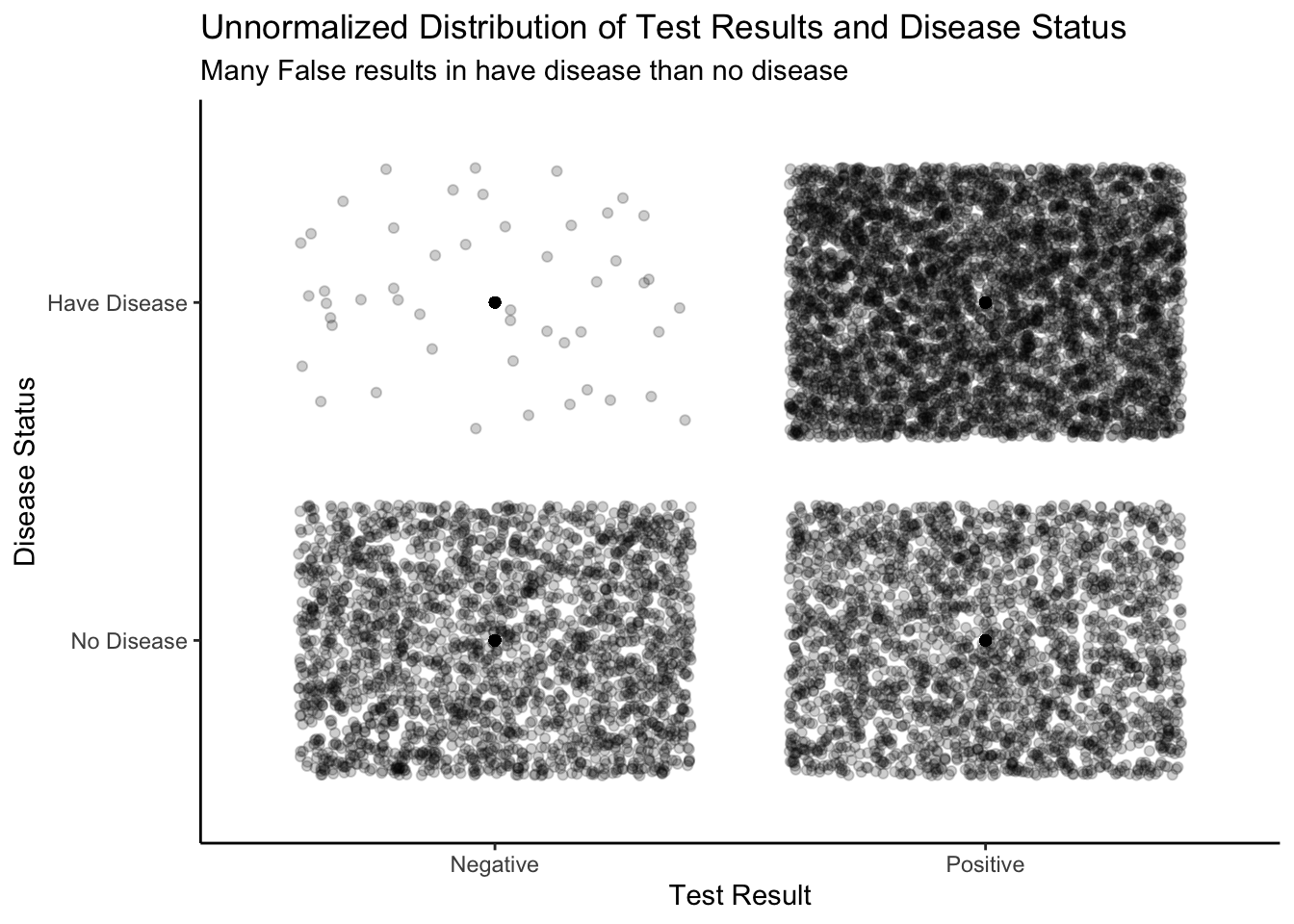
Below is a joint distribution displayed in 3D. Instead of using the “jitter” feature in R to unstack the dots, we are using a 3D plot to visualize the number of dots in each box. The number of people who correctly test negative is far greater than of the other categories. The 3D plot shows the total number of cases for each section (True positive, True negative, False positive, False negative),the 3D bar coming from those combinations. Now,pay attention to the two rows of the 3D graph, if you trying to add up the length of the 3D bar for the top two sections and the bottom two sections, they should be equal to each other, where each have 10,000 case. This is because we simulate the experience in two independent and separate world one in the have-disease world and one in the no-disease world.
Show the code
# Pile up the dots in one point.
# Later use for rayshader
jd_disease_plot <- jd_disease |>
summarize(total = n(),
.by = c(have_disease, positive_test)) |>
ggplot(aes(x = as.factor(positive_test),
y = as.factor(have_disease),
color = total)) +
geom_point(size = 5) +
scale_color_continuous(limits = c(0, 5000)) +
scale_x_discrete(breaks = c(0, 1),
labels = c("Negative", "Positive")) +
scale_y_discrete(breaks = c(FALSE, TRUE),
labels = c("No Disease", "Have Disease")) +
labs(x = "Test Result",
y = "Disease Status",
title = "Unnormalized Distribution of Results and Status",
subtitle = "Many False results in have disease than no disease",
color = "Cases") +
theme_classic() +
theme(legend.position = "none",
title = element_text(size = 7),
axis.text.x = element_text(size = 7),
axis.text.y = element_text(size = 7))
plot_gg(jd_disease_plot,
width = 3.5,
zoom = 0.65,
theta = 25,
phi = 30,
sunangle = 225,
soliddepth = -0.5,
windowsize = c(2048, 1536))
# Save the plot as an image
rgl::rgl.snapshot("probability/images/disease.png")
# Close the RGL device
rgl::close3d()
This Section is called “Two Models” because, for each person, there are two possible states of the world: have the disease or not have the disease. By assumption, there are no other outcomes. We call these two possible states of the world “models,” even though they are very simple models.
In addition to the two models, we have two possible results of our experiment on a given person: test positive or test negative. Again, this is an assumption. We do not allow for any other outcome. In coming sections, we will look at more complex situations where we consider more than two models and more than two possible results of the experiment. In the meantime, we have built the unnormalized joint distribution for models and results. This is a key point! Look back earlier in this Chapter for discussions about both unnormalized distributions and joint distributions.
We want to analyze these plots by looking at different slices. For instance, let’s say that you have tested positive for the disease. Since the test is not always accurate, you cannot be 100% certain that you have it. We isolate the slice where the test result equals 1 (meaning positive).
Show the code
jd_disease |>
filter(positive_test == 1)# A tibble: 7,484 × 3
ID have_disease positive_test
<int> <lgl> <int>
1 1 TRUE 1
2 2 FALSE 1
3 3 TRUE 1
4 4 FALSE 1
5 5 TRUE 1
6 7 TRUE 1
7 8 FALSE 1
8 9 TRUE 1
9 11 TRUE 1
10 12 FALSE 1
# ℹ 7,474 more rowsMost people who test positive are infected This is a result for common diseases like cold. We can easily create an unnormalized conditional distribution with:
Show the code
# geom_histogram won't work because we are using non-continuous value.
# geom_col won't work because need two aesthetic both x and y
# geom_bar work
jd_disease |>
filter(positive_test == 1) |>
ggplot(aes(have_disease)) +
geom_bar() +
labs(title = "Disease Status Given Positive Test",
subtitle = "Almost all of the cases were infected",
x = "Disease Status",
y = "Count") +
scale_x_discrete(breaks = c(FALSE, TRUE),
labels = c("Healthy", "Infected")) +
theme_classic()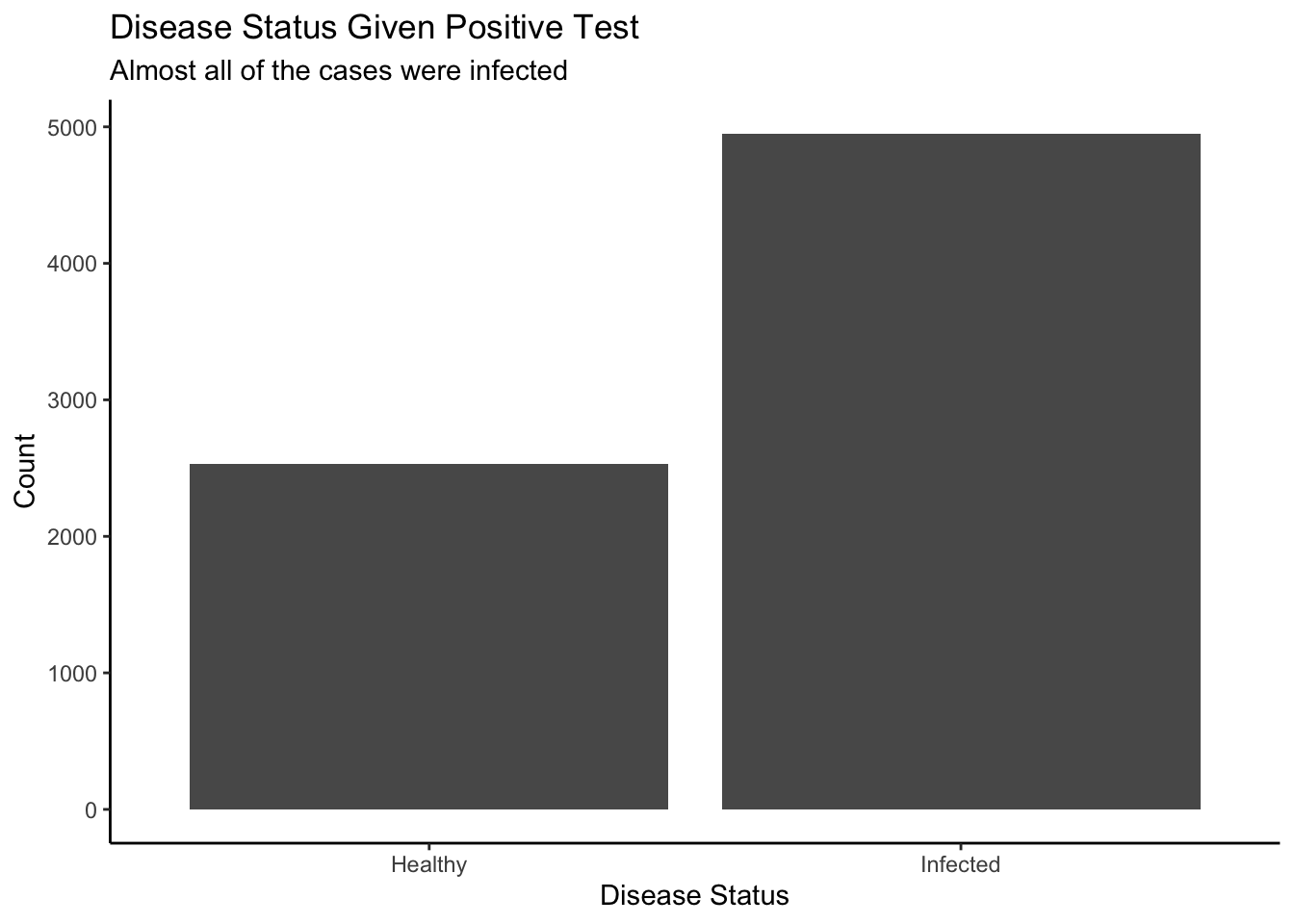
filter() transforms a joint distribution into a conditional distribution.
Turn this unnormalized distribution into a posterior probability distribution:
Show the code
# Use discrete for TRUE and FALSE
jd_disease |>
filter(positive_test == 1) |>
ggplot(aes(have_disease)) +
geom_bar(aes(y = after_stat(count/sum(count))),
color = "white") +
labs(title = "Posterior for Probophobia Conditional on Positive Test",
x = "Probophobia Status",
y = "Probability") +
scale_x_discrete(breaks = c(FALSE, TRUE),
labels = c("Healthy", "Infected")) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic() 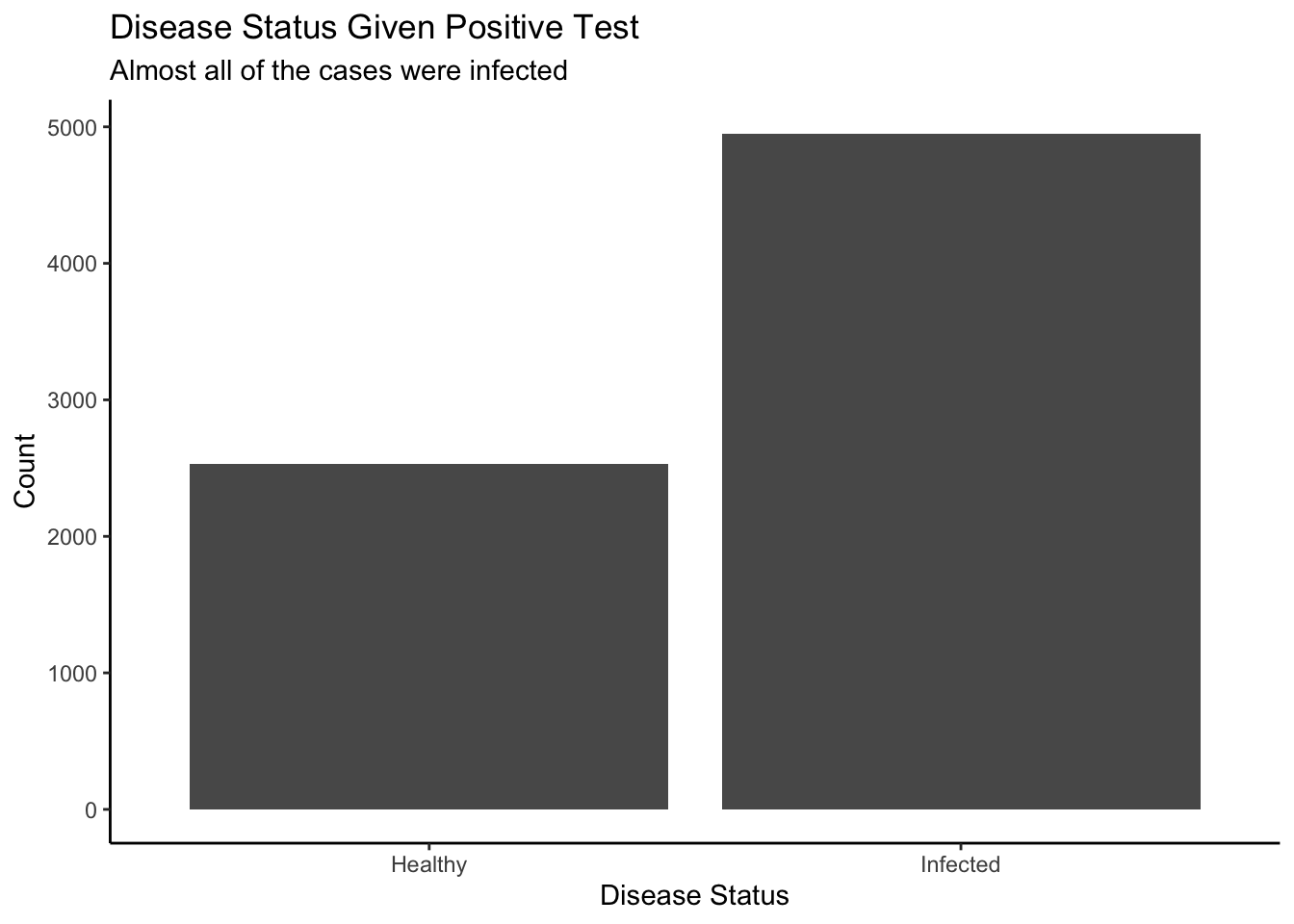
If we zoom in on the plot, about 70% of people who tested positive have the disease and 30% who tested positive do not have the disease. In this case, we are focusing on one slice of the probability distribution where the test result was positive. There are two disease outcomes: positive or negative. By isolating a section, we are looking at a conditional distribution. Conditional on a positive test, you can visualize the likelihood of actually having the disease versus not.
Now recalled the question we asked at the start of the session:
If you test positive, what is the probability that you have Probophobia?
By looking at the posterior graph we just create, we can answer this question easily:
With a positive test, you can be almost 70% sure that you have Probophobia, however there is a good chance of about 30% that you receive a false positive, so don’t worry too much, there is still about a third of hope that you get the wrong result
Now let’s consider the manipulation of this posterior, here is another question. Question : 10 people walks up to testing center, 5 of them tested negative, 5 of them tested positive, what is the probability of at least 6 people are actually healthy?
Show the code
tibble(test = 1:100000) |>
mutate(person1 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.3))) |>
mutate(person2 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.3))) |>
mutate(person3 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.3))) |>
mutate(person4 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.3))) |>
mutate(person5 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.3))) |>
mutate(person6 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.7))) |>
mutate(person7 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.7))) |>
mutate(person8 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.7))) |>
mutate(person9 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.7))) |>
mutate(person10 = map_int(test, ~ rbinom(n = 1, size = 1, p = 0.7))) |>
select(!test) |>
# The tricky part of this code is that we want to sum the outcomes across the
# rows of the tibble. This is different from our usual approach of summing
# down the columns, as with summarize(). The way to do this is to, first, use
# rowwise() to tell R that we want to work with rows in the tibble and then,
# second, use c_across() to indicate which variables we want to work with.
rowwise() |>
mutate(total = sum(c_across(person1:person10))) |>
ggplot(aes(total)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 1,
color = "white") +
scale_x_continuous(breaks = c(0:10)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
theme_classic() 
2.4 Three models

Imagine that your friend gives you a bag with two marbles. There could either be two white marbles, two black marbles, or one of each color. Thus, the bag could contain 0% white marbles, 50% white marbles, or 100% white marbles. The proportion, \(p\), of white marbles could be, respectively, 0, 0.5, or 1.
Question: What is the chance of the bag contains exactly two white marbles, given that when we selected the marbles three times, every time we select a white marble?
\[ P(\text{2 White Marbles in bag | White Marbles Sampled = 3} ) \] Just as during the Probophobia models, in order to answer this question, we need to start up with the simulated data and then graph out the joint distribution of this scenario because we need to consider all possible outcomes of this model, and then based on the joint distribution we can slice out the the part we want (the conditional distribution) in the end making a posterior graph as well as normalizing it to see the probability.
Step 1: Simulate the data into an tibble
Let’s say you take a marble out of the bag, record whether it’s black or white, then return it to the bag. You repeat this three times, observing the number of white marbles you see out of three trials. You could get three whites, two whites, one white, or zero whites as a result of this trial. We have three models (three different proportions of white marbles in the bag) and four possible experimental results. Let’s create 3,000 draws from this joint distribution:
Show the code
# Create the joint distribution of the number of white marbles in the bag
# (in_bag) and the number of white marbles pulled out in the sample (in_sample),
# one-by-one. in_bag takes three possible values: 0, 1 and 2, corresponding to
# zero, one and two white marbles potentially in the bag.
set.seed(3)
sims <- 10000
# We also start off with a tibble. It just makes things easier
jd_marbles <- tibble(ID = 1:sims) |>
# For each row, we (randomly!) determine the number of white marbles in the
# bag. We do not know why the `as.integer()` hack is necessary. Shouldn't
# `map_int()` automatically coerce the result of `sample()` into an integer?
mutate(in_bag = map_int(ID, ~ as.integer(sample(c(0, 1, 2),
size = 1)))) |>
# Depending on the number of white marbles in the bag, we randomly draw out 0,
# 1, 2, or 3 white marbles in our experiment. We need `p = ./2` to transform
# the number of white marbles into the probability of drawing out a white
# marble in a single draw. That probability is either 0%, 50% or 100%.
mutate(in_sample = map_int(in_bag, ~ rbinom(n = 1,
size = 3,
p = ./2)))
jd_marbles# A tibble: 10,000 × 3
ID in_bag in_sample
<int> <int> <int>
1 1 0 0
2 2 1 3
3 3 2 3
4 4 1 1
5 5 2 3
6 6 2 3
7 7 1 0
8 8 2 3
9 9 0 0
10 10 1 2
# ℹ 9,990 more rowsStep 2: Plot the joint distribution:
Show the code
# The distribution is unnormalized. All we see is the number of outcomes in each
# "bucket." Although it is never stated clearly, we are assuming that there is
# an equal likelihood of 0, 1 or 2 white marbles in the bag.
jd_marbles |>
ggplot(aes(x = in_sample, y = in_bag)) +
geom_jitter(alpha = 0.5) +
labs(title = "Black and White Marbles",
subtitle = "More white marbles in bag mean more white marbles selected",
x = "White Marbles Selected",
y = "White Marbles in the Bag") +
scale_y_continuous(breaks = c(0, 1, 2)) +
theme_classic()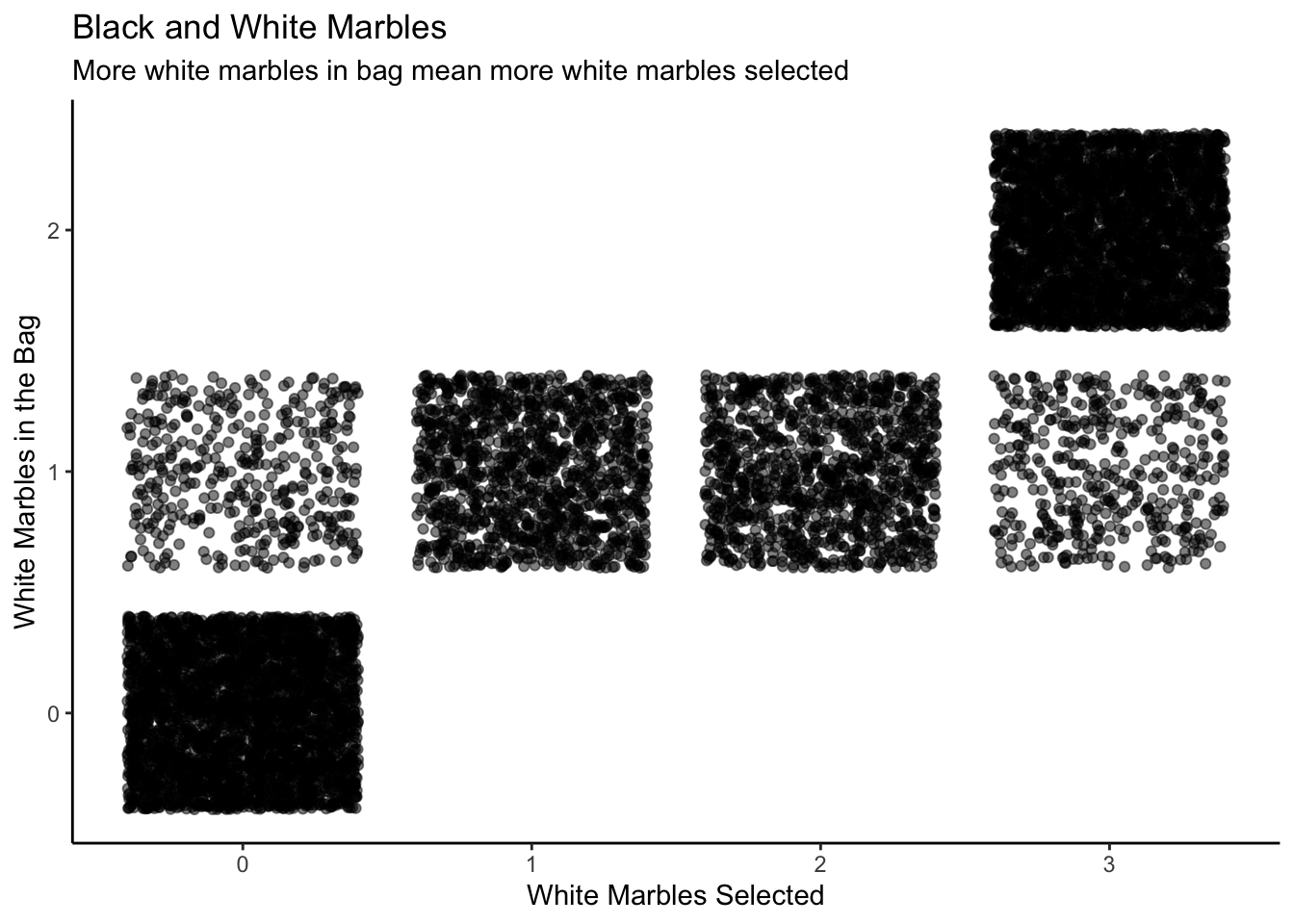
Here is the 3D visualization:
Show the code
# Same process, first condense point plot to a single plot, then use plot_gg make it 3d and
# give height.
jd_marbles_plot <- jd_marbles |>
summarize(total = n(),
.by = c(in_bag, in_sample)) |>
mutate(in_sample = as.factor(in_sample)) |>
mutate(in_bag = as.factor(in_bag)) |>
ggplot(aes(x = in_sample, y = in_bag, color = total)) +
geom_point() +
scale_color_continuous(limits = c(0, 3500)) +
labs(x = "White Marbles Selected",
y = "White Marbles in the Bag",
title = "Black and White Marbles",
subtitle = "More white marbles in bag mean more are selected",
color = "Count") +
theme(legend.position = "none",
title = element_text(size = 7),
axis.text.x = element_text(size = 6),
axis.text.y = element_text(size = 6))
plot_gg(jd_marbles_plot,
width = 4,
zoom = 0.75,
theta = 25,
phi = 30,
sunangle = 225,
soliddepth = -0.5,
raytrace = FALSE,
windowsize = c(2048,1536))
# Save the plot as an image
rgl::rgl.snapshot("probability/images/marbles.png")
# Close the RGL device
rgl::close3d()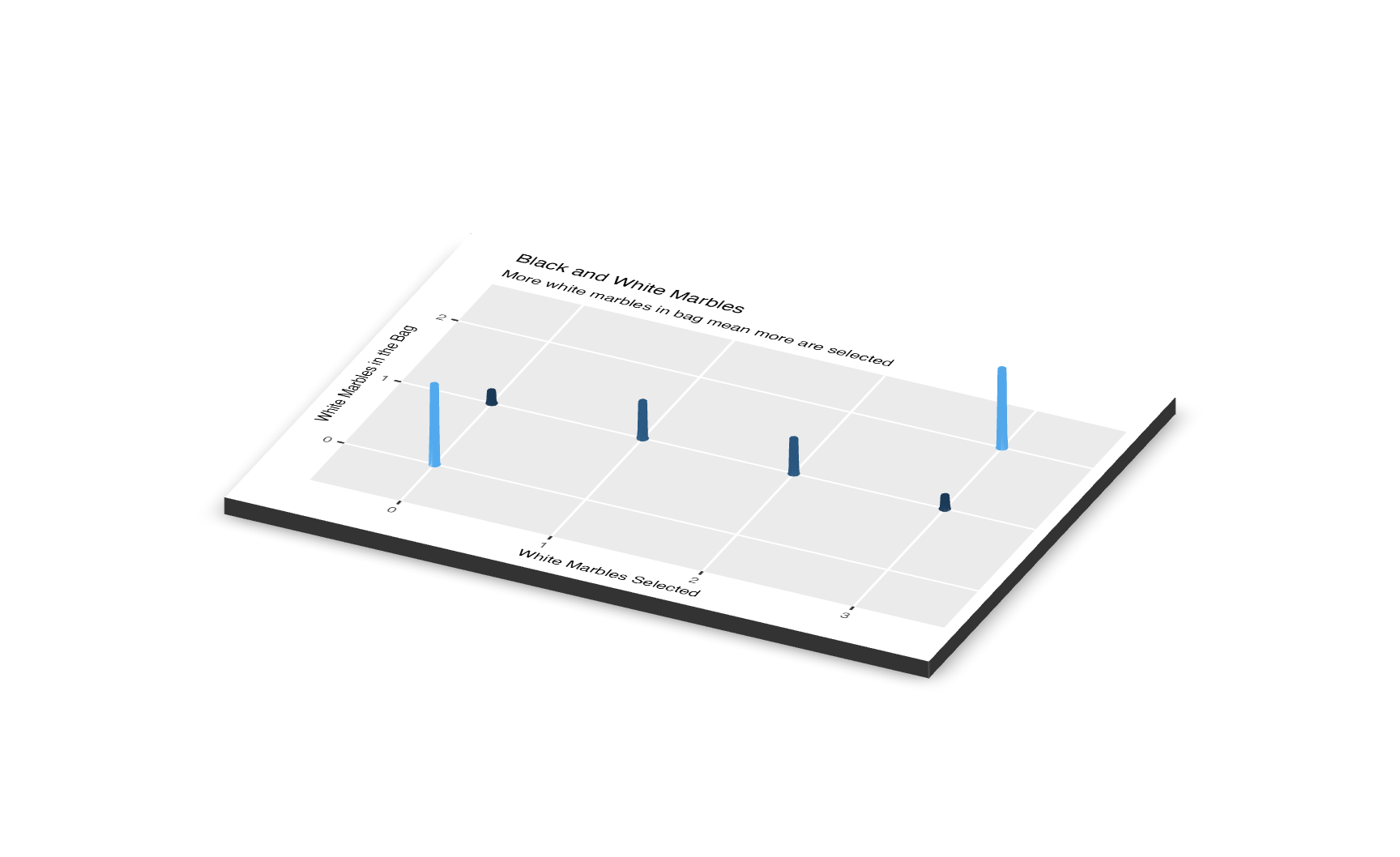
The y-axes of both the scatterplot and the 3D visualization are labeled “Number of White Marbles in the Bag.” Each value on the y-axis is a model, a belief about the world. For instance, when the model is 0, we have no white marbles in the bag, meaning that none of the marbles we pull out in the sample will be white.
Now recalls the question, we essentially only care about the fourth column in the joint distribution (x-axis=3) because the question is asking us to create a conditional distribution given that fact that 3 marbles were selected. Therefore, we could isolate the slice where the result of the simulation involves three white marbles and zero black ones. Here is the unnormalized probability distribution.
Step 3: Plot the unnormalized conditional distribution.
Show the code
# The key step is the filter. Creating a conditional distribution from a joint
# distribution is the same thing as filtering that joint distribution for a
# specific value. A conditional distribution is a "slice" of the joint
# distribution, and we take that slice with filter().
jd_marbles |>
filter(in_sample == 3) |>
ggplot(aes(in_bag)) +
geom_histogram(binwidth = 0.5, color = "white") +
labs(title = "Unnormalized Conditional Distribution",
subtitle = "Number of white marbles in bag given that three were selected in the sample",
x = "Number of White Marbles in the Bag",
y = "Count") +
coord_cartesian(xlim = c(0, 2)) +
scale_x_continuous(breaks = c(0, 1, 2)) +
theme_classic()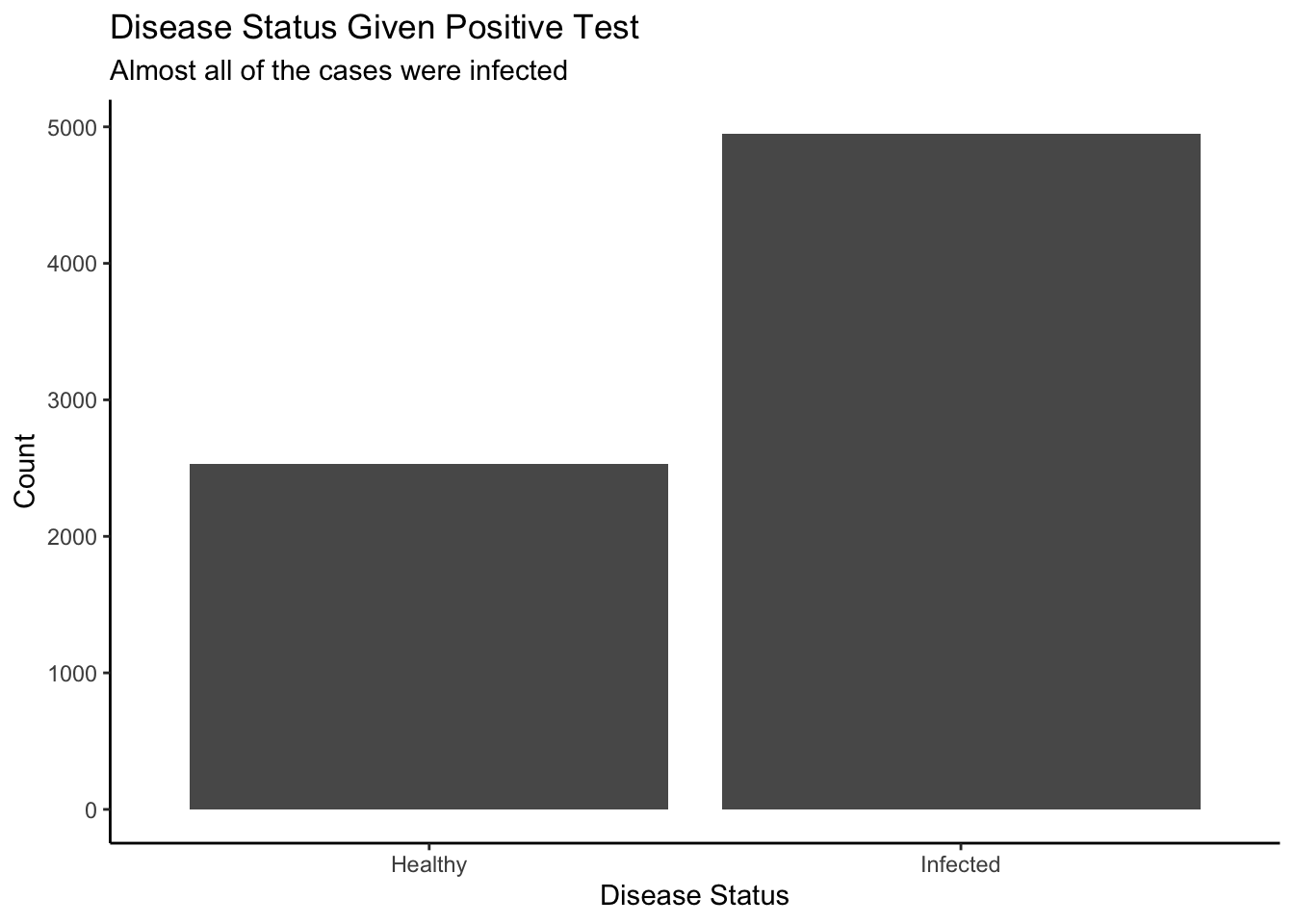
Step 4: Plot the normalize posterior distribution. Next, let’s normalize the distribution.
Show the code
jd_marbles |>
filter(in_sample == 3) |>
ggplot(aes(in_bag)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
binwidth = 0.5,
color = "white") +
labs(title = "Posterior Probability Distribution",
subtitle = "Number of white marbles in bag given that three were selected in the sample",
x = "Number of White Marbles in the Bag",
y = "Probability") +
coord_cartesian(xlim = c(0, 2)) +
scale_x_continuous(breaks = c(0, 1, 2)) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()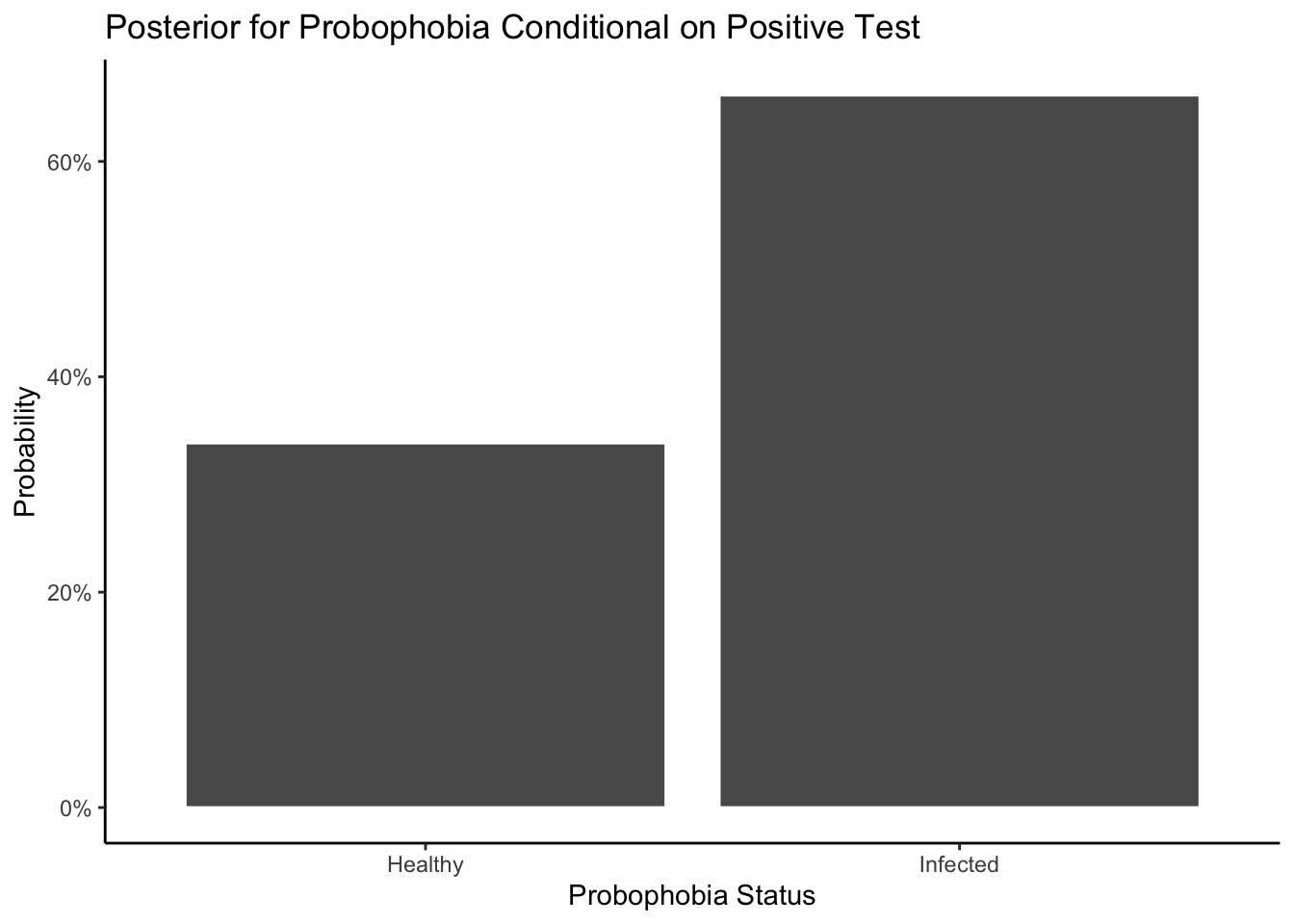
This plot makes sense because when all three marbles you draw out of the bag are white, there is a pretty good chance that there are no black marbles in the bag. But you can’t be certain! It is possible to draw three white even if the bag contains one white and one black. However, it is impossible that there are zero white marbles in the bag.
Lastly let’s answer the question: What is the chance of the bag contains exactly two white marbles, given that when we selected the white marbles three times, everytime we select a white marble?
Answer: As the Posterior Probability Distribution shows (x-axis=2), the chance of the bag contains exactly two white marbles given that we select 3 white marbles out of three tries is about 85%.
2.5 N models
Assume that there is a coin with \(\rho_h\). We guarantee that there are only 11 possible values of \(\rho_h\): \(0, 0.1, 0.2, ..., 0.9, 1\). In other words, there are 11 possible models, 11 things which might be true about the world. This is just like situations we have previously discussed, except that there are more models to consider.
We are going to run an experiment in which you flip the coin 20 times and record the number of heads. What does this result tell you about the value of \(\rho_h\)? Ultimately, we will want to calculate a posterior distribution of \(\rho_h\), which is written as p(\(\rho_h\)).
Question: What is the probability of getting exactly 8 heads out of 20 tosses?
To start, it is useful to consider all the things which might happen if, for example, \(\rho_h = 0.4\). Fortunately, the R functions for simulating random variables makes this easy.
Show the code
set.seed(9)
sims <- 1000
x <- tibble(ID = 1: sims, heads = rbinom(n = 1000, size = 20, p = 0.4))
x |>
ggplot(aes(heads)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
bins = 50) +
labs(title = "Empirical Distribution of Number of Heads",
subtitle = "Based on 1,000 simulations with p = 0.4",
x = "Number of Heads out of 20 Tosses",
y = "Probability") +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()
First, notice that many different things can happen! Even if we know, for certain, that \(\rho_h = 0.4\), many outcomes are possible. Life is remarkably random. Second, the most likely result of the experiment is 8 heads, as we would expect. Third, we have transformed the raw counts of how many times each total appeared into a probability distribution. Sometimes, however, it is convenient to just keep track of the raw counts. The shape of the figure is the same in both cases.
Show the code
x |>
ggplot(aes(heads)) +
geom_histogram(bins = 50) +
labs(title = "Total Count of the Number of Heads Out of 20 Tosses",
subtitle = "Based on 1,000 simulations with p = 0.4",
x = "Number of Heads out of 20 Tosses",
y = "Count") +
theme_classic()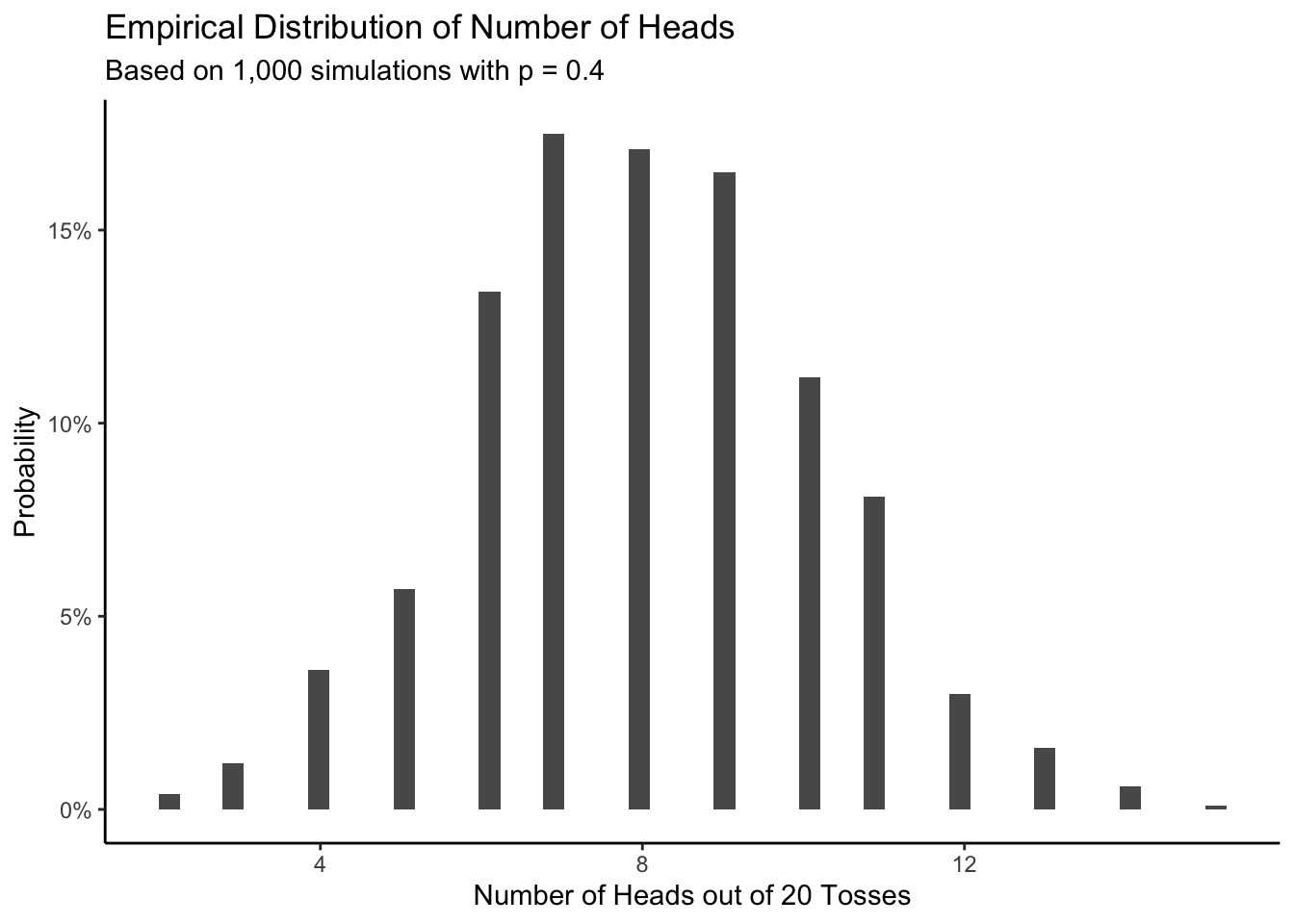
Either way, the figures show what would have happened if that model — that \(\rho_h = 0.4\) — were true.
We can do the same thing for all 11 possible models, calculating what would happen if each of them were true. This is somewhat counterfactual since only one of them can be true. Yet this assumption does allow us to create the joint distribution of models which might be true and of data which our experiment might generate. Let’s simplify this as p(models, data), although you should keep the precise meaning in mind.
Show the code
# sims size depends on your data size, or the number in rep().
set.seed(10)
sims <- 11000
jd_coin <- tibble(ID = 1:sims, p = rep(seq(0, 1, 0.1), 1000)) |>
mutate(heads = map_int(p, ~ rbinom(n = 1, size = 20, p = .)))
jd_coin |>
ggplot(aes(y = p, x = heads)) +
geom_jitter(alpha = 0.1) +
labs(title = "Empirical Distribution of Number of Heads",
subtitle = expression(paste("Based on simulations with various values of ", rho[h])),
x = "Number of Heads out of 20 Tosses",
y = expression(rho[h])) +
scale_y_continuous(breaks = seq(0, 1, 0.1)) +
theme_classic()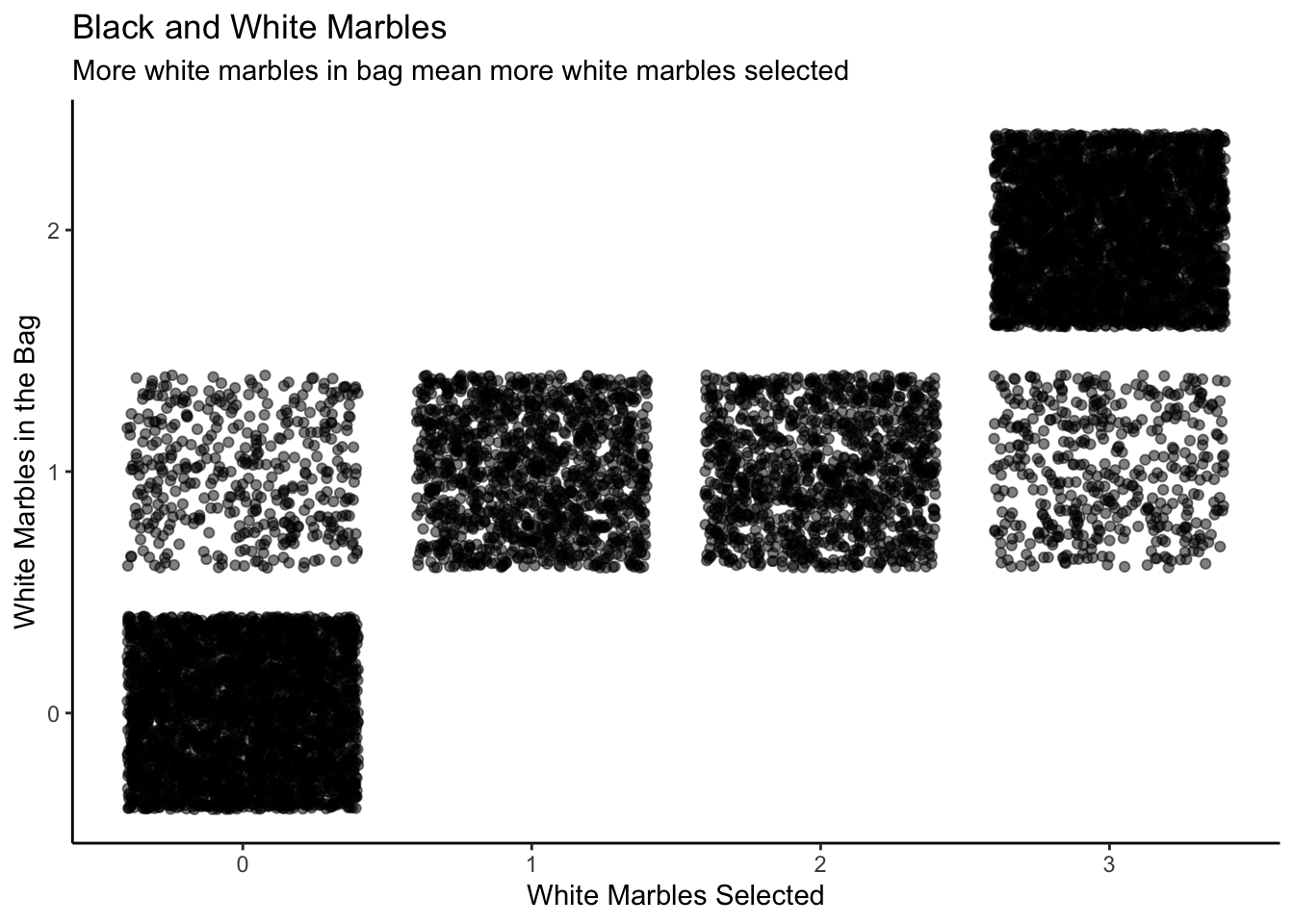
Here is the 3D version of the same plot.
Show the code
# Condese point and make rayshader plot.
jd_coin_plot <- jd_coin |>
summarize(total = n(),
.by = c(p, heads)) |>
mutate(p = as.factor(p)) |>
mutate(heads = as.factor(heads)) |>
ggplot() +
geom_point(aes(x = heads, y = p, color = total)) +
scale_color_continuous(limits = c(0, 1000)) +
theme(legend.position = "none") +
labs(x = "Number of Heads out of 20 Tosses",
y = expression(rho[h]),
title = "Empirical Distribution of Number of Heads",
subtitle = expression(paste("Based on simulations with various values of ",
rho[h]))) +
theme(title = element_text(size = 9),
axis.text.x = element_text(size = 7),
axis.title.y = element_text(size = 7),
legend.position = "none")
plot_gg(jd_coin_plot,
width = 3.5,
zoom = 0.65,
theta = 25,
phi = 30,
sunangle = 225,
soliddepth = -0.5,
raytrace = FALSE,
windowsize = c(2048,1536))
# Save the plot as an image
rgl::rgl.snapshot("probability/images/coin.png")
# Close the RGL device
rgl::close3d()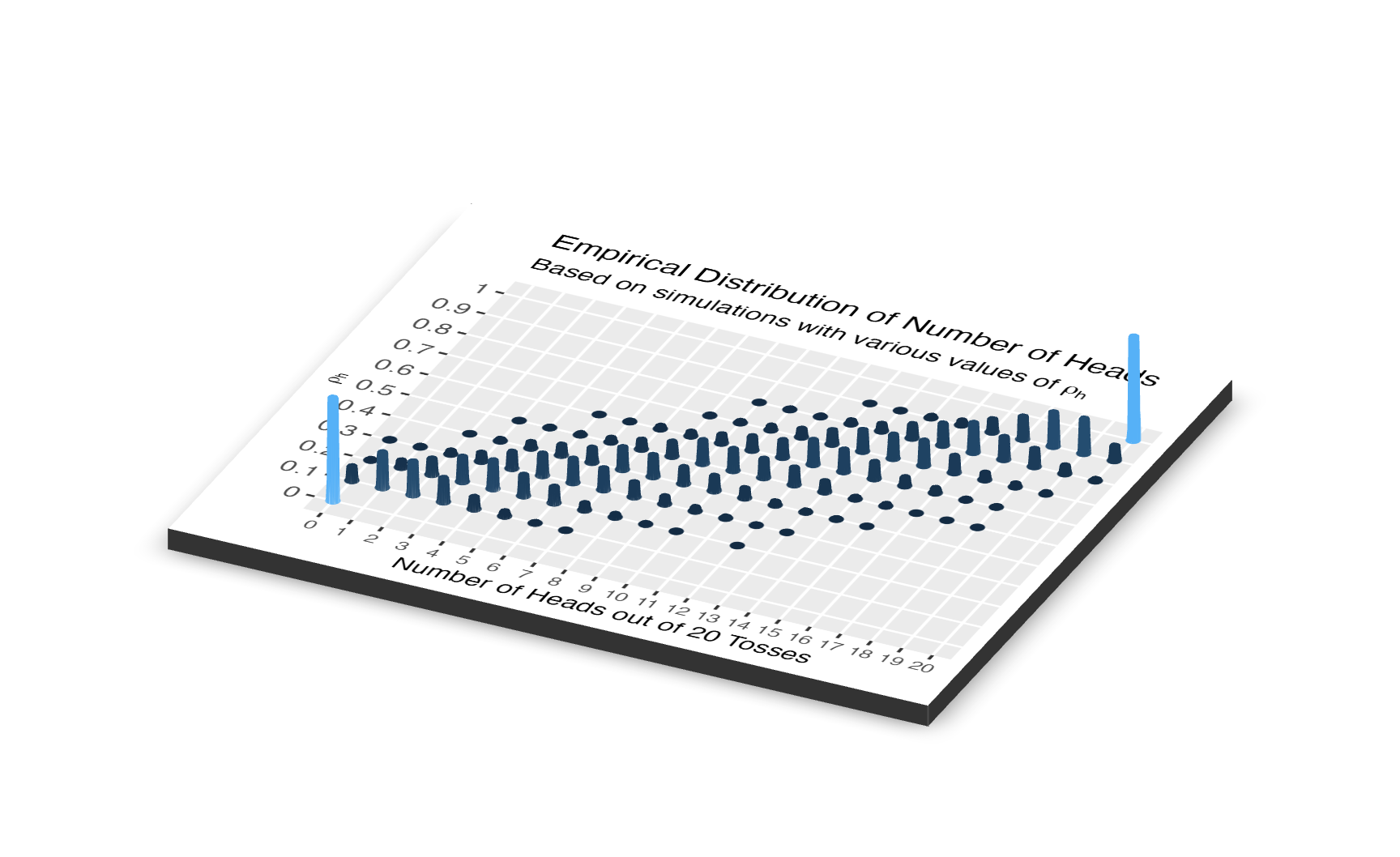
In both of these diagrams, we see 11 models and 21 outcomes. We don’t really care about the p(\(models\), \(data\)), the joint distribution of the models-which-might-be-true and the data-which-our-experiment-might-generate. Instead, we want to estimate \(p\), the unknown parameter which determines the probability that this coin will come up heads when tossed. The joint distribution alone can’t tell us that. We created the joint distribution before we had even conducted the experiment. It is our creation, a tool which we use to make inferences. Instead, we want the conditional distribution, p(\(models\) | \(data = 8\)). We have the results of the experiment. What do those results tell us about the probability distribution of \(p\)?
To answer this question, we simply take a vertical slice from the joint distribution at the point of the x-axis corresponding to the results of the experiment.
This animation shows what we want to do with joint distributions. We take a slice (the red one), isolate it, rotate it to look at the conditional distribution, normalize it (change the values along the current z-axis from counts to probabilities), then observe the resulting posterior.
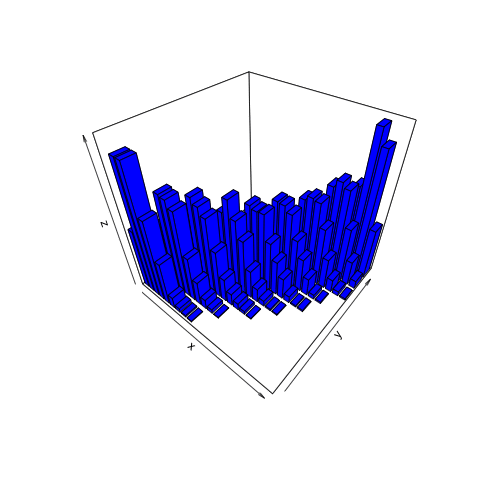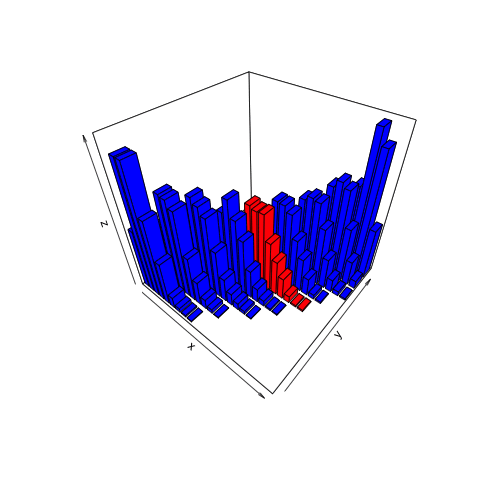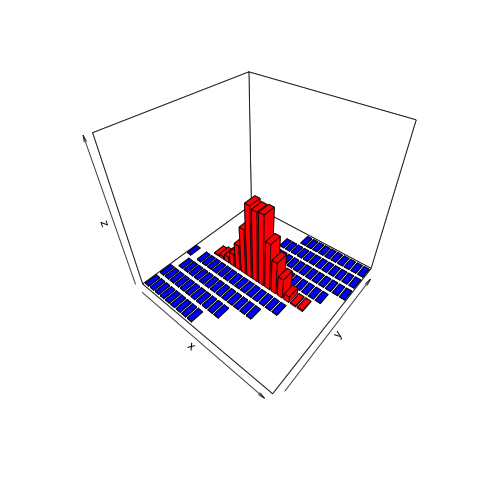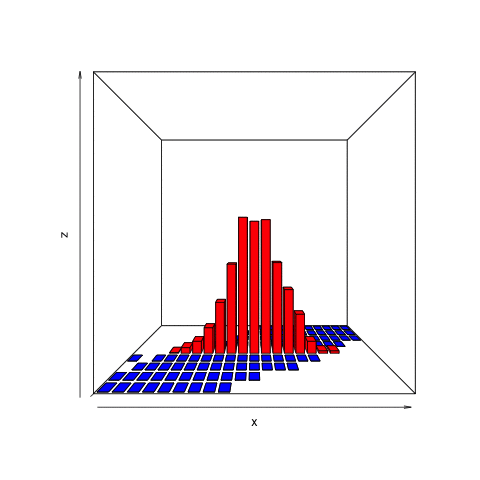
This is the only part of the joint distribution that we care about. We aren’t interested in what the object looks like where, for example, the number of heads is 11. That portion is irrelevant because we observed 8 heads, not 11. By using the filter function on the simulation tibble we created, we can conclude that there are a total of 465 times in our simulation in which 8 heads were observed.
As we would expect, most of the time when 8 coin tosses came up heads, the value of \(p\) was 0.4. But, on numerous occasions, it was not. It is quite common for a value of \(p\) like 0.3 or 0.5 to generate 8 heads. Consider:
Show the code
jd_coin |>
filter(heads == 8) |>
ggplot(aes(p)) +
geom_bar() +
labs(title = expression(paste("Values of ", rho[h], " Associated with 8 Heads")),
x = expression(paste("Assumed value of ", rho[h], " in simulation")),
y = "Count") +
theme_classic()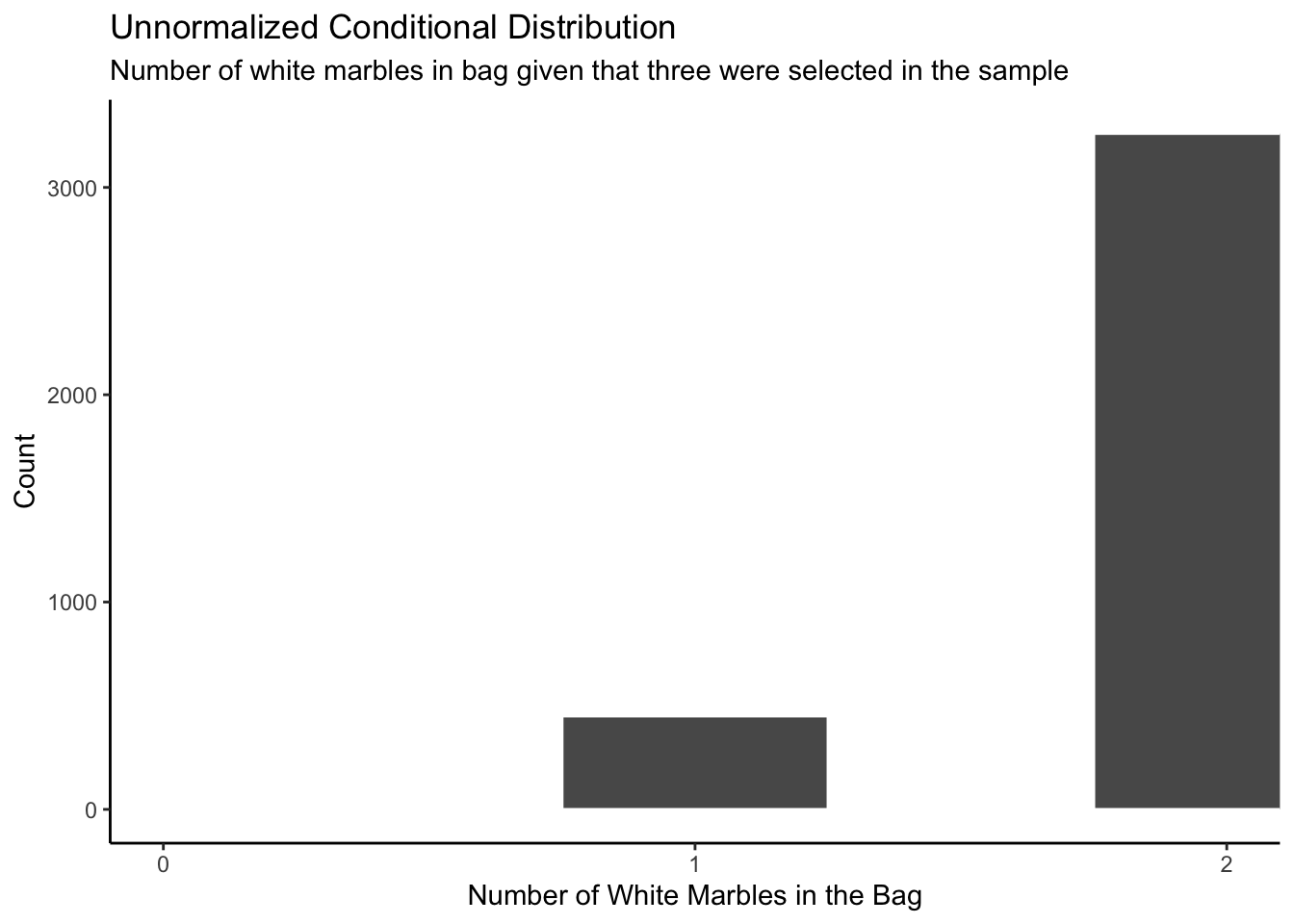
Yet this is a distribution of raw counts. It is an unnormalized density. To turn it into a proper probability density (i.e., one in which the sum of the probabilities across possible outcomes sums to one) we just divide everything by the total number of observations.
Show the code
jd_coin |>
filter(heads == 8) |>
ggplot(aes(x = p)) +
geom_histogram(aes(y = after_stat(count/sum(count))),
bins = 50) +
labs(title = expression(paste("Posterior Probability Distribution of ", rho[h])),
x = expression(paste("Possible values for ", rho[h])),
y = "Probability") +
scale_x_continuous(breaks = seq(0.2, 0.7, by = 0.1)) +
scale_y_continuous(labels =
scales::percent_format(accuracy = 1)) +
theme_classic()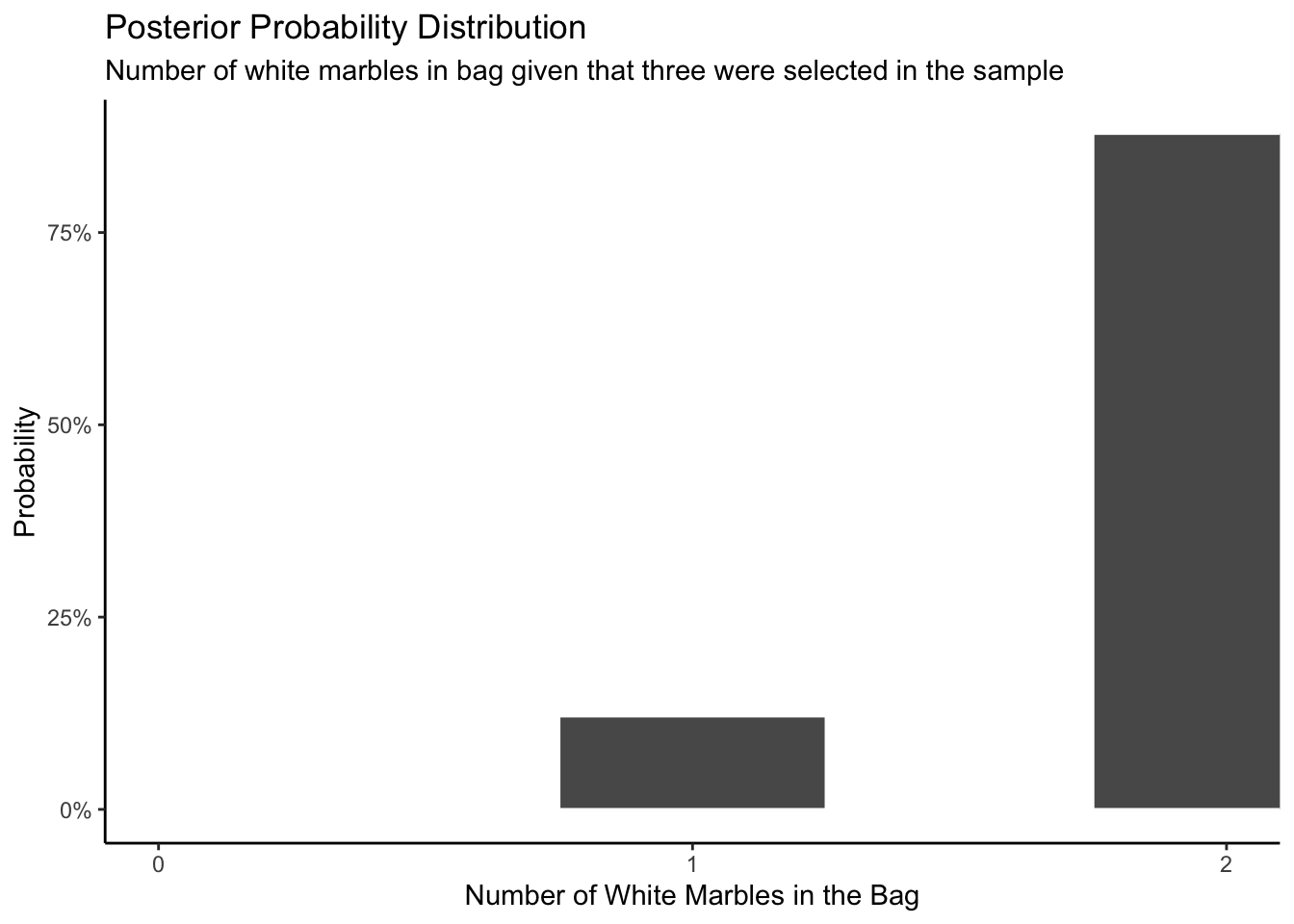
Solution:
The most likely value of \(\rho_h\) is 0.4, as before. But, it is much more likely that \(p\) is either 0.3 or 0.5. And there is about an 8% chance that \(\rho_h \ge 0.6\).
You might be wondering: what is the use of a model? Well, let’s say we toss the coin 20 times and get 8 heads again. Given this result, we can ask: What is the probability that future samples of 20 flips will result in 10 or more heads?
There are three main ways you could go about solving this problem with simulations.
The first wrong way to do this is assuming that \(\rho_h\) is certain because we observed 8 heads after 20 tosses. We would conclude that 8/20 gives us 0.4. The big problem with this is that you are ignoring your uncertainty when estimating \(\rho_h\). This would lead us to the following code.
Show the code
# A tibble: 10,000,000 × 3
sim_ID heads above_ten
<int> <int> <lgl>
1 1 10 TRUE
2 2 5 FALSE
3 3 2 FALSE
4 4 10 TRUE
5 5 5 FALSE
6 6 10 TRUE
7 7 7 FALSE
8 8 11 TRUE
9 9 9 FALSE
10 10 9 FALSE
# ℹ 9,999,990 more rowsShow the code
odds |>
ggplot(aes(x=heads,fill=above_ten))+
geom_histogram(aes(y = after_stat(count/sum(count))),bins = 50)+
scale_fill_manual(values = c('grey50', 'red'))+
labs(title = "Posterior Probability Distribution (Wrong Way)",
subtitle = "Number of heads in 20 tosses",
x = "Number of heads",
y = "Probability",
fill = "Above ten heads") +
scale_x_continuous(labels = scales::number_format(accuracy = 1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
theme_classic()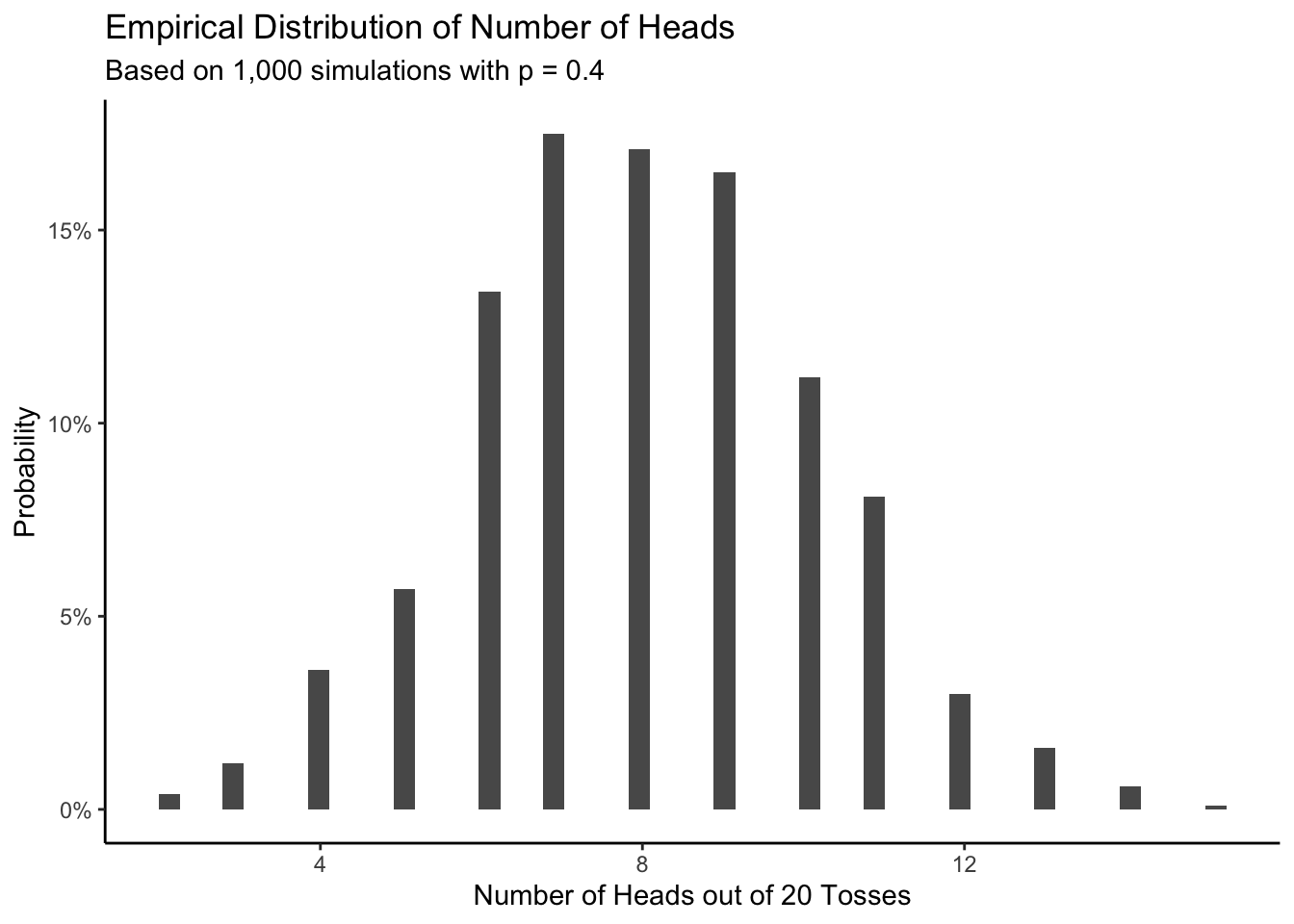
Using this Posterior distribution derived from the (wrong way) simulated data, the probability results with 10 or more heads is
# A tibble: 1 × 1
success
<dbl>
1 0.245about 24.5%.
The second method involves sampling the whole posterior distribution vector we previously created. This would lead to the following correct code.
Show the code
p_draws <- tibble(p = rep(seq(0, 1, 0.1), 1000)) |>
mutate(heads = map_int(p, ~ rbinom(n = 1, size = 20, p = .))) |>
filter(heads == 8)
odds_2nd <- tibble(p = sample(p_draws$p, size = sims, replace = TRUE)) |>
mutate(heads = map_int(p, ~ rbinom(n = 1, size = 20, p = .))) |>
mutate(above_ten = if_else(heads >= 10, TRUE, FALSE))
odds_2nd# A tibble: 10,000,000 × 3
p heads above_ten
<dbl> <int> <lgl>
1 0.4 7 FALSE
2 0.3 8 FALSE
3 0.5 13 TRUE
4 0.4 10 TRUE
5 0.4 6 FALSE
6 0.5 8 FALSE
7 0.5 9 FALSE
8 0.5 12 TRUE
9 0.5 10 TRUE
10 0.4 8 FALSE
# ℹ 9,999,990 more rowsShow the code
odds_2nd |>
ggplot(aes(x = heads,fill = above_ten))+
geom_histogram(aes(y = after_stat(count/sum(count))),bins = 50)+
scale_fill_manual(values = c('grey50', 'red'))+
labs(title = "Posterior Probability Distribution (Right Way)",
subtitle = "Number of heads in 20 tosses",
x = "Number of heads",
y = "Probability",
fill = "Above ten heads") +
scale_x_continuous(labels = scales::number_format(accuracy = 1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
theme_classic()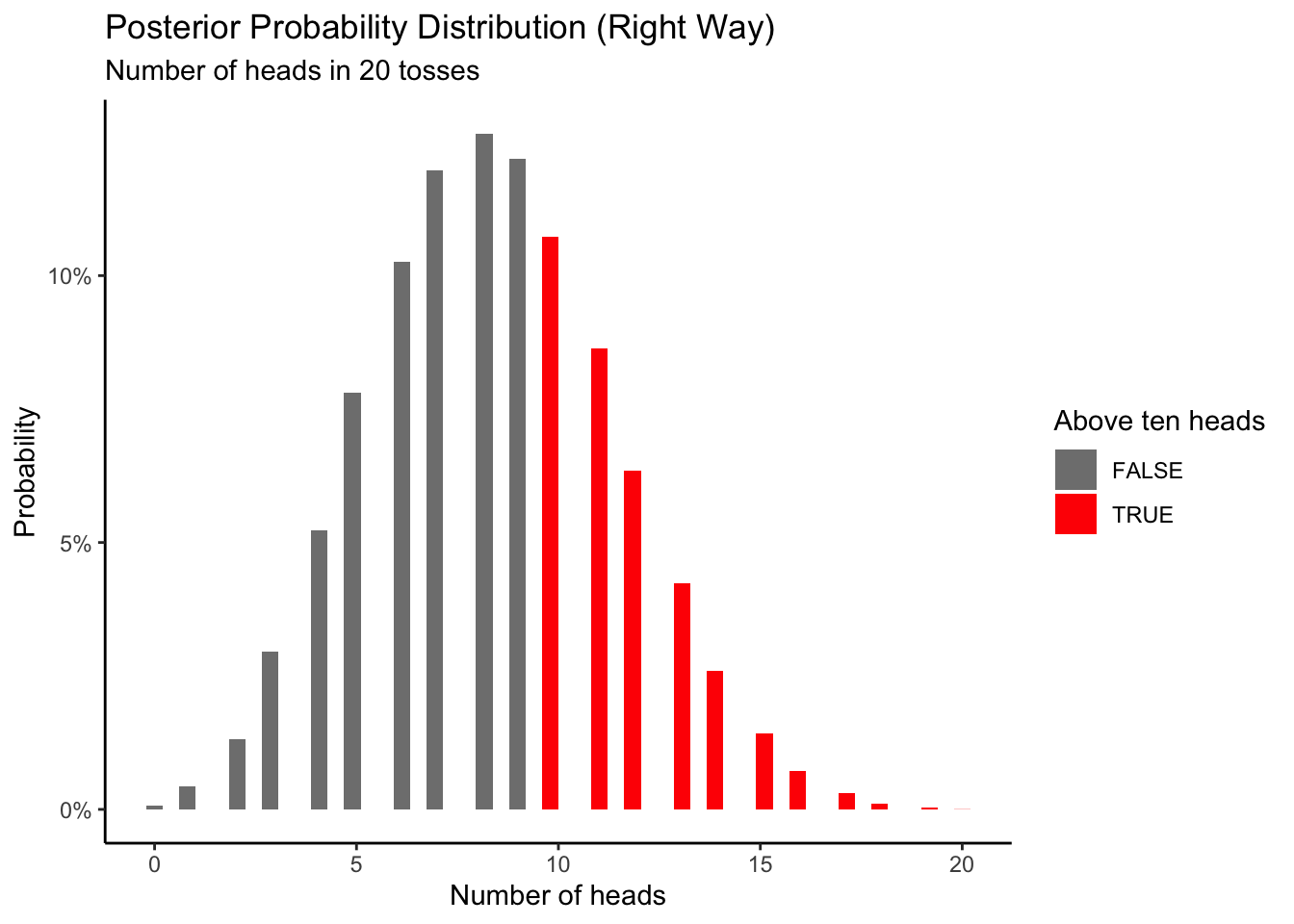
Using this Posterior distribution derived from the (right way 1st) simulated data, the probability results in 10 or more head is
# A tibble: 1 × 1
success
<dbl>
1 0.351about 32.8%
As you may have noticed, if you calculated the value using the first method, you would believe that getting 10 or more heads is less likely than it really is. If you were to run a casino based on these assumptions, you will lose all your money. It is very important to be careful about the assumptions you are making. We tossed a coin 20 times and got 8 heads. However, you would be wrong to assume that \(\rho_h\) = 0.4 just based on this result.
2.6 Cardinal Virtues
The four Cardinal Virtues are Wisdom, Justice, Courage, and Temperance. Because data science is, ultimately, a moral act, we use these virtues to guide our work. Every data science project begins with a question.
Wisdom starts by creating the Preceptor Table. What data, if we had it, would allow us to answer our question easily? If the Preceptor Table has one outcome, then the model is predictive. If it has more than one (potential) outcome, then the model is causal. We then explore the data we have. You can never look too closely at your data. Key question: Are the data we have close enough to the data we want (i.e., the Preceptor Table) that we can consider both as coming from the same population? If not, we can’t proceed further. Key in making that decision is the assumption of validity. Do the columns in the Preceptor Table match the columns in the data?
Justice starts with the Population Table – the data we want to have (i.e., the Preceptor Table), the data which we actually have, and all the other data from that same population. Each row of the Population Table is defined by a unique Unit/Time combination. We explore three key issues about the Population Table. First, does the relationship among the variables demonstrate stability, meaning is the model stable across different time periods? Second, are the rows associated with the data and, separately, the rows associated with the Preceptor Table representative of all the units from the population? Third, for causal models only, we consider unconfoundedness.
Courage allows us to explore different models. Justice gave us the Population Table. Courage creates the data generating mechanism. We begin with the basic mathematical structure of the model. With that structure in mind, we decide which variables to include. We estimate the values of the unknown parameters. We avoid hypothesis tests. We check our models for consistency with the data we have. We select one model.
Temperance guides us in the use of the model we have created to answer the questions with which we began. We create posteriors of quantities of interest. We should be modest in the claims we make. Humility is important. The posteriors we create are never the “truth.” The assumptions we made to create the model are never perfect. Yet decisions made with flawed posteriors are almost always better than decisions made without them.
2.6.1 Wisdom

Wisdom requires the creation of a Preceptor Table, some exploratory data analysis, and a determination, using the concept of validity, as to whether or not we can (reasonably!) assume that the two come from the same population.
Wisdom helps us decide if we can even hope to answer our question with the data that we have.
A Preceptor Table is smallest possible table with rows and columns such that, if there is no missing data, our question is easy to answer.
One key aspect of this Preceptor Table is whether or not we need more than one potential outcome in order to calculate our estimand. For example, if we want to know the causal effect of exposure to Spanish-speakers on attitude toward immigration then we need a causal model, one which estimates that attitude for each person under both treatment and control. The Preceptor Table would require two columns for the outcome. If, on the other hand, we only want to predict someone’s attitude, or compare one person’s attitude to another person’s, then we would only need a Preceptor Table with one column for the outcome.
Every model is predictive, in the sense that, if we give you new data — and it is drawn from the same population — then you can create a predictive forecast. But only a subset of those models are causal, meaning that, for a given individual, you can change the value of one input and figure out what the new output would be and then, from that, calculate the causal effect by looking at the difference between two potential outcomes.
With prediction, all we care about is forecasting \(Y\) given \(X\) on some as-yet-unseen data. But there is no notion of “manipulation” in such models. We don’t pretend that, for Joe, we could turn variable \(X\) from a value of \(5\) to a value of \(6\) by just turning some knob and, by doing so, cause Joe’s value of \(Y\) to change from \(17\) to \(23\). We can compare two people (or two groups of people), one with \(X\) equal to \(5\) and one with \(X\) equal to \(6\), and see how they differ in \(Y\). The basic assumption of predictive models is that there is only one possible \(Y\) for Joe. There are not, by assumption, two possible values for \(Y\) for Joe, one if \(X\) equals \(5\) and another if \(X\) equals \(6\). The Preceptor Table has a single column under \(Y\) if that is all we need to answer the question.
With causal inference, however, we can consider the case of Joe with \(X = 5\) and Joe with \(X = 6\). The same mathematical model can be used. And both models can be used for prediction, for estimating what the value of \(Y\) will be for a yet-unseen observation with a specified value for \(X\). But, in this case, instead of only a single column in the Preceptor Table for \(Y\), we have at least two (and possibly many) such columns, one for each of the potential outcomes under consideration.
The difference between predictive models and causal models is that the former have one column for the outcome variable and the latter have more than one column.
Second, we look at the data we have and perform an exploratory data analysis, an EDA. You can never look at your data too much. The most important variable is the one we most want to understand/explain/predict. In the models we create in later chapters, this variable will go on the left-hand side of our mathematical equations. Some academic fields refer to this as the “dependent variable.” Others use terms like “response” or “outcome.” Whatever the terminology, we need to explore the distribution of this variable, its min/max/range, its mean and median, its standard deviation, and so on.
Gelman, Hill, and Vehtari (2020) write:
Most important is that the data you are analyzing should map to the research question you are trying to answer. This sounds obvious but is often overlooked or ignored because it can be inconvenient. Optimally, this means that the outcome measure should accurately reflect the phenomenon of interest, the model should include all relevant predictors, and the model should generalize to the cases to which it will be applied.
For example, with regard to the outcome variable, a model of incomes will not necessarily tell you about patterns of total assets. A model of test scores will not necessarily tell you about child intelligence or cognitive development. …
We care about other variables as well, especially those that are most correlated/connected with the outcome variable. The more time that we spend looking at these variables, the more likely we are to create a useful model.
Third, the (almost always imaginary) population is key. We need the data we want — the Preceptor Table — and the data we have to be similar enough that we can consider them as all having come from the same statistical population. From Wikipedia:
In statistics, a population is a set of similar items or events which is of interest for some question or experiment. A statistical population can be a group of existing objects (e.g. the set of all stars within the Milky Way galaxy) or a hypothetical and potentially infinite group of objects conceived as a generalization from experience (e.g. the set of all opening hands in all the poker games in Las Vegas tomorrow).
Mechanically, assuming that the Preceptor Table and the data are drawn from the same population is the same thing as “stacking” the two on top of each other. For that to make sense, the variables must mean the same thing — at least mostly — in both cases. This is the assumption of validity.
If we assume that the data we have is drawn from the same population as the data in the Preceptor Table is drawn from, then we can use information about the former to make inferences about the latter. We can combine the Preceptor Table and the data into a single Population Table. If we can’t do that, if we can’t assume that the two sources come from the same population, then we can’t use our data to answer our questions. The heart of Wisdom is knowing when to walk away. As John Tukey noted:
The combination of some data and an aching desire for an answer does not ensure that a reasonable answer can be extracted from a given body of data.
2.6.2 Justice

Justice concerns four topics: the Population Table, stability, representativeness, and unconfoundedness.
The Population Table includes a row for each unit/time combination in the underlying population from which both the Preceptor Table and the data are drawn. It can be constructed if the validity assumption is (mostly) true. It includes all the rows from the Preceptor Table. It also includes the rows from the data set. It usually has other rows as well, rows which represent unit/time combinations from other parts of the population.
There are three key issues to explore in any Population Table: stability, representativeness and unconfoundedness.
Stability means that the relationship between the columns in the Population Table is the same for three categories of rows: the data, the Preceptor Table, and the larger population from which both are drawn.
Never forget the temporal nature of almost all real data science problems. Our Preceptor Table will focus on rows for today or for the near future. The data we have will always be from before now. We must almost always assume that the future will be like the past in order to use data from the past to make predictions about the future.
Representativeness, or the lack thereof, concerns two relationship, among the rows in the Population Table. The first is between the Preceptor Table and the other rows. The second is between our data and the other rows. Ideally, we would like both the Preceptor Table and our data to be random samples from the population. Sadly, this is almost never the case.
Validity is about the columns in our Population Table. Stability and representativeness are about the rows.
Unconfoundedness means that the treatment assignment is independent of the potential outcomes, when we condition on pre-treatment covariates. This assumption is only relevant for causal models. We describe a model as “confounded” if this is not true. The easiest way to ensure unconfoundedness is to assign treatment randomly.
2.6.3 Courage

Courage begins with the exploration and testing of different models. It concludes with the creation of the Data Generating Mechanism.
Courage begins by a discussion of the functional form we will be using. This is usually straight-forward because it follows directly from the type of the outcome variable: continuous implies a linear model, binary implies logistic, and more than two categories suggests multinomial logistic. We provide the mathematical formula for this model, using y and x as variables. The rest of the discussion is broken up into three sections: “Models,” “Tests,” and “Data Generating Mechanism.”
Courage requires math.
The three languages of data science are words, math and code, and the most important of these is code.
We need to explain the structure of our model using all three languages, but we need Courage to implement the model in code.
Courage requires us to take the general mathematical formula and then make it specific. Which variables should we include in the model and which do we exclude? Every data science project involves the creation of several models, each with one or more unknown parameters.
Code allows us to “fit” a model by estimating the values of the unknown parameters. Sadly, we can never know the true values of these parameters. But, like all good statisticians, we can express our uncertain knowledge in the form of posterior probability distributions. With those distributions, we can compare the actual values of the outcome variable with the “fitted” or “predicted” results of the model. We can examine the “residuals,” the difference between the fitted and actual values.
A parameter is something which does not exist in the real world. (If it did, or could, then it would be data.) Instead, a parameter is a mental abstraction, a building block which we will use to to help us accomplish our true goal: To replace at least some of the questions marks in the actual Preceptor Table. Since parameters are mental abstractions, we will always be uncertain as to their value, however much data we might collect.
Randomness is intrinsic to this fallen world.
Null hypothesis testing is a mistake. There is only the data, the models and the summaries therefrom.
The final step of Courage is to select the final model, the Data Generating Mechanism.
2.6.4 Temperance

Temperance uses the Data Generating Mechanism to answer the specific question with which we began. Humility reminds us that this answer is always a lie. We can also explore the general question by using the DGM to calculate many similar quantities of interest, displaying the results graphically.
There are few more important concepts in statistics and data science than the Data Generating Mechanism. Our data — the data that we collect and see — has been generated by the complexity and confusion of the world. God’s own mechanism has brought His data to us. Our job is to build a model of that process, to create, on the computer, a mechanism which generates fake data consistent with the data which we see. With that DGM, we can answer any question which we might have. In particular, with the DGM, we provide predictions of data we have not seen and estimates of the uncertainty associated with those predictions. We can fill in the missing values in the Preceptor Table and then, easily, calculate all Quantities of Interest.
Justice gave us the Population Table. Courage created the DGM, the fitted model. Temperance will guide us in its use.
Having created (and checked) a model, we now use the model to answer questions. Models are made for use, not for beauty. The world confronts us. Make decisions we must. Our decisions will be better ones if we use high quality models to help make them.
Sadly, our models are never as good as we would like them to be. First, the world is intrinsically uncertain.

There are known knowns. There are things we know we know. We also know there are known unknowns. That is to say, we know there are some things we do not know. But there are also unknown unknowns, the ones we do not know we do not know. – Donald Rumsfeld
What we really care about is data we haven’t seen yet, mostly data from tomorrow. But what if the world changes, as it always does? If it doesn’t change much, maybe we are OK. If it changes a lot, then what good will our model be? In general, the world changes some. That means that our forecasts are more uncertain that a naive use of our model might suggest.
In Temperance, the key distinction is between the true posterior distribution — what we will call “Preceptor’s Posterior” — and the estimated posterior distribution. Recall our discussion from Section 2.1. Imagine that every assumption we made in Wisdom and Justice were correct, that we correctly understand every aspect of how the world works. We still would not know the unknown value we are trying to estimate — recall the Fundamental Problem of Causal Inference — but the posterior we created would be perfect. That is Preceptor’s Posterior. Sadly, even if our estimated posterior is, very close to Preceptor’s Posterior, we can never be sure of that fact, because we can never know the truth, never be certain that all the assumptions we made are correct.
Even worse, we must always worry that our estimated posterior, despite all the work we put into creating it, is far from the truth. We, therefore, must be cautious in our use of that posterior, humble in our claims about its accuracy. Using our posterior, despite its faults, is better than not using it. Yet it is, at best, a distorted map of reality, a glass through which we must look darkly. Use your posteriors with humility.